はじめに
こんにちは、ラクスル事業所属で現在はグループ会社である株式会社ダンボールワンで開発をリードしている岸野です。
今回はモノリスなシステムをマイクロサービス化していく際に生じるデータベースの分離・移行という頭を悩ませる課題に対して、Debeziumというソフトウェアを利用することで少し楽にしてみようという試みについてご紹介します。
課題背景
ラクスルではRPP(Raksul Platform Project)としてモノリスで巨大なPHPのシステムをマイクロサービスに切り分けるということを行っています。一般的にデータベースを複数アプリケーション間で共有することはバッドプラクティスと言われており、ラクスルでもマイクロサービス化と同時にデータベースの切り出しを行っております。
そういったモノリスなシステムのデータベースを切り出す際に問題になることとしてデータの移行や同期が挙げられます。
例えばもともとモノリス側にある機能と新しく切り出したマイクロサービス側の機能をバチッと切り替えるとモノリス側にある既存データが失われてしまいます。失われても良いデータであれば問題がありませんが注文履歴など移行後も参照を続けたい場合に困ります。

この問題の解決策には様々な物があると思いますが、この記事では事前にデータの移行と同期を行ったうえで実際に動かすシステムを新システム側に切り替えるというパターンについて言及します。
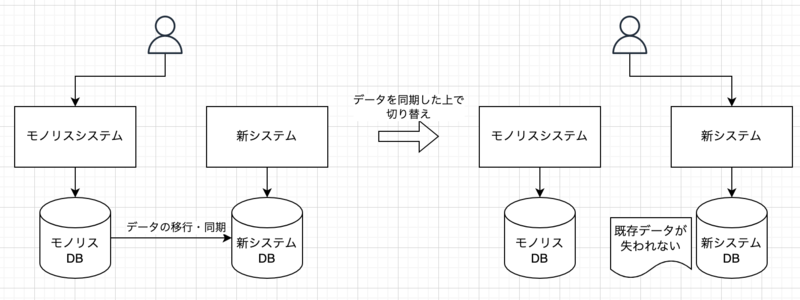
データの移行・同期と言ってもこちらも様々なやり方があるでしょう。
- データベースのダンプ・リストア
- 定期バッチによる差分更新
- ストアドプロシージャ・トリガーによる変更検知とデータの移行プロセスの呼び出し
- モノリスシステムから新旧両方のデータベースに対して書き込む
例えば新旧でデータベースエンジンが異なる、テーブルスキーマが異なる、よりリアルタイムに変更を同期する必要があるといった場合に上記の手段では難しいかもしれません。
そこで今回ご紹介するのがDebezium https://debezium.io/ というソフトウェアを使ったデータ同期の仕組みづくりです。
Debeziumとは
RedHat社が開発しているオープンソースソフトウェアで既存データベース上の変更を即座に検知しイベントとしてKafkaに記録することができます。Debezium自体はKafka connectとして実装されておりMySQL、PostgreSQL、MongoDBなど様々なデータベースエンジンに対応しています。
特徴として既存アプリケーション・データベースに手を加えること無くDebeziumを導入することができるので既存システムの再構築・移行に向いています。
例として以下のように構成することでモノリスDB側の変更を即座に新システムDBに反映する仕組みを作ることができます。
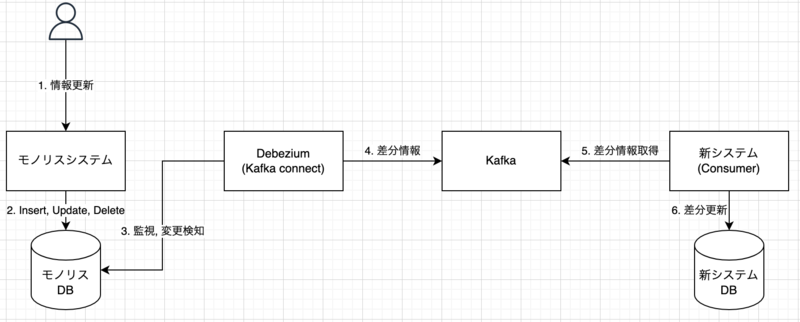
Railsプロジェクトに導入してみる
構成
それでは実際に2つのRailsアプリケーション間でデータベースの同期を行う仕組みを作ってみます。サンプルコードはこちらです https://github.com/YusukeKishino/debezium-rails-sample
サンプルコードは以下のような構成になっています。
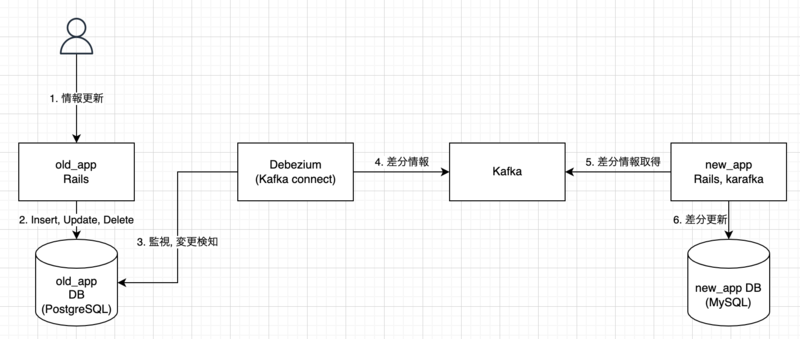
Debeziumを用いることで異なるデータベース間でのデータ同期が行えるためold_appにはPostgreSQLを使用しnew_appにはMySQLを使用しています。
また、スキーマが異なるテーブル間でもnew_app側でスキーマの変換を行えるので以下のような2つのテーブルを用意しました。
old_app/db/migrate/20211203083448_create_users.rb
class CreateUsers < ActiveRecord::Migration[6.1]
def change
create_table :users do |t|
t.string :name
t.timestamps
end
end
end
new_app/db/migrate/20211203084401_create_users.rb
class CreateUsers < ActiveRecord::Migration[6.1]
def change
create_table :users do |t|
t.string :first_name
t.string :last_name
t.timestamps
end
end
end
基本的にold_appもnew_appもrails new —minimalとrails g scaffold user name:stringで作成した簡単なCRUDアプリケーションになっています。
karafka gem
Kafkaに貯められたデータを取得(consume)するために利用しているのがkarafka gem https://github.com/karafka/karafka になります。karafkaはKafkaベースのRubyアプリケーションの開発を容易にするためのフレームワークです。karafkaはRailsベースのアプリケーションをはじめどのようなアプリケーションにも組み込めます。
使用方法の細かい説明は省きますが以下のようにKafka上のtopicとそれに対するconsumerを紐付けるような形で使用します。
new_app/karafka.rb
...
consumer_groups.draw do
topic 'old_app_development.public.users' do
consumer UserConsumer
end
end
...
new_app/app/consumers/user_consumer.rb
class UserConsumer < ApplicationConsumer
def consume
params_batch.each do |message|
puts "Message payload: #{message.payload}"
data = message.payload['payload']['after']
puts data
name = data['name'].split(' ')
user = User.find_or_initialize_by(id: data['id'])
user.assign_attributes(first_name: name.first, last_name: name.last)
user.save!
end
end
end
この例ではold_appではnameの1カラムにまとまっている名前をnew_appのテーブルスキーマであるfirst_nameとlast_nameに分けて保存する実装になっています。このようにconsumer側でテーブルスキーマの差異を吸収できるのでデータ移行に向いているのではないかと思います。
Debeziumの設定
Debeziumの起動後はAPIを用いて操作します。Debeziumにはconnectorという概念があります。connectorにはどのデータベースのどのデータをどのようにキャプチャするかなどを設定します。
- どのデータベースを: データベースエンジンや接続情報の設定
- どのデータを: データベース全体や特定のテーブルに絞るなどキャプチャ範囲の設定
- どのように: 新規の変更のみや既存データ含めすべてのデータなど同期方法の設定
詳細はドキュメントを参照ください。https://debezium.io/documentation/reference/1.7/
以下の例ではold_appのPostgreSQLデータベースに対して既存含めすべてのデータを同期するような設定を行っています。
curl --location --request POST 'localhost:8083/connectors/' \
--header 'Accept: application/json' \
--header 'Content-Type: application/json' \
--data-raw '{
"name": "test-connector",
"config": {
"connector.class": "io.debezium.connector.postgresql.PostgresConnector",
"tasks.max": "1",
"database.hostname": "postgres",
"database.port": "5432",
"database.user": "raksul",
"database.password": "password",
"database.dbname": "old_app_development",
"database.server.name": "old_app_development",
"plugin.name": "pgoutput"
}
}'
デモ
それでは実際に動かしながら挙動を見てみます。
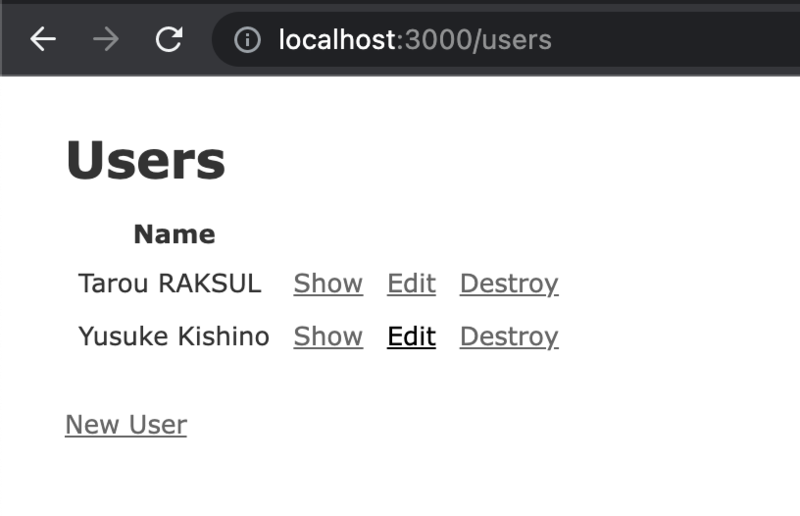
まず各アプリケーションを立ち上げるとold_appにはTarou RAKSULとYusuke Kishinoの2つのレコードがあり、new_app側にはレコードが存在していない状態です。
(分かりづらいですが3000ポートがold_app, 3001がnew_appになります。)

ここでDebeziumに対してold_appのデータをKafkaに同期するように上記curlコマンドを実行します。そうすると既存データの内容がKafkaに連携されkarafkaでは以下のようなデータを受け取ることができます。こちらも詳細は省きますがテーブルの構造情報や現在のデータの内容が記載されています。
{
"schema" => {
"type" => "struct",
"fields" => [
{
"type" => "struct",
"fields" => [
{
"type" => "int64",
"optional" => false,
"default" => 0,
"field" => "id"
},
...
長いので中略
...
},
"payload" => {
"before" => nil,
"after" => {
"id" => 1,
"name" => "Tarou RAKSUL",
"created_at" => 1638963127972413,
"updated_at" => 1638963127972413
},
"source" => {
"version" => "1.7.1.Final",
"connector" => "postgresql",
"name" => "old_app_development",
"ts_ms" => 1638963144898,
"snapshot" => "true",
"db" => "old_app_development",
"sequence" => "[null,\"23547008\"]",
"schema" => "public",
"table" => "users",
"txId" => 564,
"lsn" => 23547008,
"xmin" => nil
},
"op" => "r",
"ts_ms" => 1638963144898,
"transaction" => nil
}
}
この情報をもとにnew_app側でデータを更新してあげることで以下のように既存データの移行に成功しました。
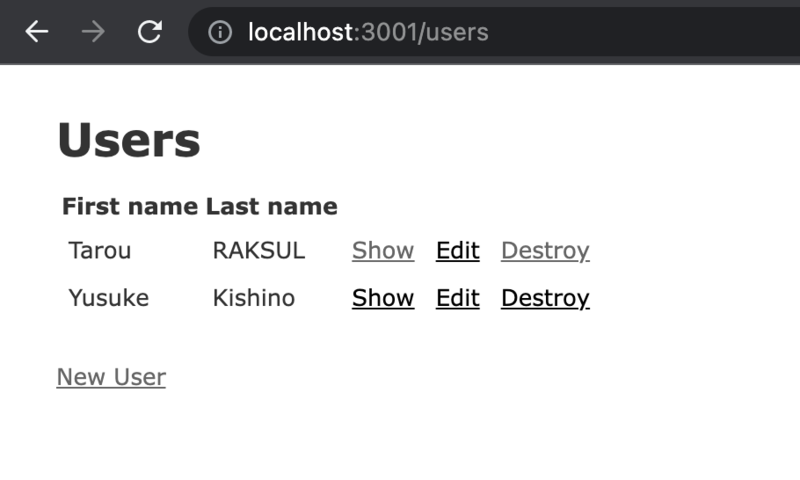
次は新規データの追加と更新を試してみます。

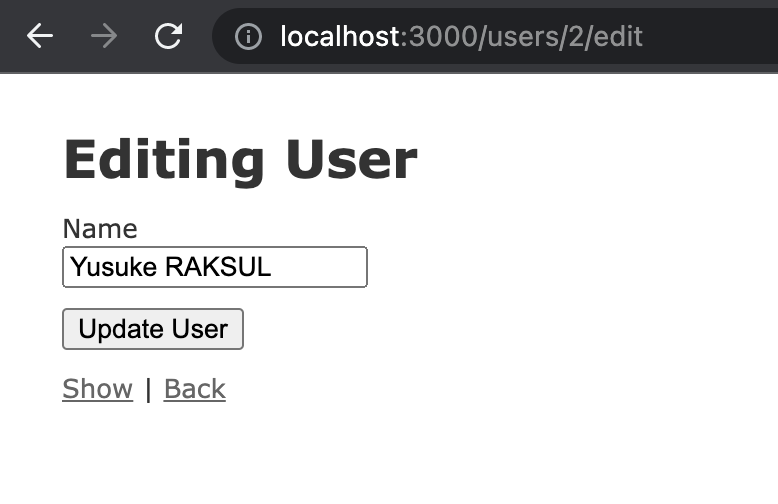

新規データの登録と既存ユーザー情報の更新を行いました。するとこの場合も同様にKafkaに変更が連携され、new_app側で処理をすることで以下のように最新の状態に追従することができました。

レコードが削除された際の実装は今回行っていませんが削除された際の挙動をConsumerに実装すれば問題なく動くと思います。
終わり
このDebeziumを使用したデータベース同期の仕組みは現在検証段階でこれから本番利用を試みようとしている段階です。それによりさらなる知見を得る事ができたら、またご紹介をしたいと思います。