はじめに
ラクスルグループジョーシス株式会社のデータ分析チームの「麦茶22」です。
ジョーシスは2021年9月にプロダクトをローンチし、2022年2月に Data Analytics Team が発足し、自分は2022年4月にチームに入りました。
チームに参加して初めてのタスクは、データウェアハウスを Single Source of Truth とする分析基盤をつくることでした。背景として、これまではアプリケーションの分析用 DB を Redash に接続して分析していましたが、データソースが増えたことや、クエリ・レポートの数が増えて管理しづらなくなったことがあり、チームの発足と合わせて分析基盤も整えることになりました。
本記事では、このタスクの一貫として行った、 RDS <-> BigQuery 間の連携をどのように構築したかをご紹介します。
前提
ジョーシスのアプリケーションは AWS 上で構築されていて、データベースは RDS を使用しています。
アプリケーションに接続する本番環境のデータベースと、分析用のデータベースが分かれていて、データウェアハウスに繋ぐのは後者です。
また、本タスクの前段階として、ウェアハウス・ETL ツールの選定がしてあり、それぞれ BigQuery と Fivetran に決まっていました。
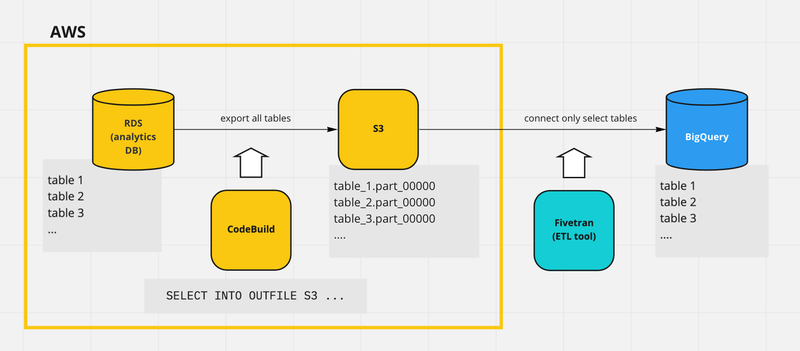
RDS (分析用データベース) -> Fivetran -> BigQuery
RDS → Fivetran のアーキテクチャを考える
アプリケーションデータを BigQuery に流すために、まずデータベースである RDS と、ETL ツール の Fivetran との連携を考えました。
RDS と Fivetran の連携には大きく分けて、
- RDS を直接 Fivetran に連携する
- RDS のデータを S3 にエクスポートしてから、S3 と Fivetran を連携する
の2つが考えられました。
はじめは (1) の方法で考えていたのですが、
- 踏み台サーバーを EC2 に新たに構築・メンテナンスする工数
- binlog によるパフォーマンス影響
の要因から、(2) の RDS のデータを一旦 S3 にエクスポートする方法を採用しました。
なお、(1) の方法では EC2 を立てずに AWS PrivateLink で RDS と接続する方法も提供されていましたが、Fivetran の最上位プランが必要だったためこちらもコスト面の理由から採用しませんでした。
RDS → S3 のエクスポートを考える
RDS ではなく、S3 のバケットを Fivetran に接続することが決まったので、次に RDS のデータをどのように S3 に移すかを考えました。
こちらも選択肢が2つありました。
既に RDS の機能として提供されている 1 の方がシンプルに実装できそうでしたが、問題としてアプリケーション DB にはレコードの変更記録を残す数百万件の大きさのイミュータブルなテーブルがあります。
これを毎回エクスポートして Fivetran で同期しようとすると、無駄が多いだけでなく、Fivetran の料金もかさんでしまいます (Fivetran の料金は従量課金で、月当たり何行のデータを取り込んだかにもとづいて計算されます)。
そこで、前回の同期分と今回の同期分の差分のみを同期対象とし、Fivetran では append_only モードを使用することを考えました。このモードでは、名前のとおり既存のレコードは変更せず、新しく同期した分を追記します。

こうすると、毎回全データを更新するのではなく、新しく追加されたレコードのみをデータウェアハウスに追加でき、利用料金も低く抑えられます。
このとき、下記の通りスナップショットのエクスポートでは、エクスポートの対象をテーブル単位までしか制御できないため、2の SELECT INTO OUTFILE S3 の方法を採用しました。
[Partial] を選択すると、スナップショットの特定部分がエクスポートされます。スナップショットのどの部分をエクスポートするかを特定するには、[Identifiers] (識別子) に 1 つ以上のデータベース、スキーマ、またはテーブルをスペースで区切って入力します。
日次ジョブの実行を考える
AWS 側の最後の工程として、 SELECT INTO OUTFILE S3 を日次で実行するサービスを選定しました。
候補として、
- Lambda
- ECS タスク
- CodeBuild
の3つがありました。
まず、Lambda のデメリットとして15分の実行時間の制限があります。将来的にテーブル数が増えたりジョブが複雑になって実行時間が伸びた場合、アーキテクチャを再度変更するための工数がかかるため、Lambda は採用しませんでした。
また、ECS タスクを採用した場合、アプリケーションのバックエンドの ECS からタスクを実行することになります。
しかし、この ECS は普段は本番環境の RDS と接続しているため、 SELECT INTO OUTFILE S3 を実行するときに接続先 DB を切り替え、再度戻す必要があります。
この設定の変更とテストを考えると、工数が大きくなることが予想され、かつ本番環境に影響する可能性もあったため、 ECS タスクも採用せず、最後の候補の CodeBuild でジョブを実行することにしました。
ここまで決定したアーキテクチャをまとめると、
- CodeBuild で
SELECT INTO OUTFILE S3を実行し、 - RDS の各テーブルについて、差分または全てのレコードを S3 にエクスポートする
となります。
Fivetran → BigQuery
以上の AWS の設定が終わり、Fivetran と S3 のコネクタを必要なテーブルに対して作成すると、同期が日次で実行されるようになります。
BigQuery へのデータのロードについては、 Fivetran の最初の設定で既に ETL 先のデータウェアハウスが選択されているため、追加の設定は必要ありませんでした。
コネクタを作成した各テーブルについて、BigQuery 上のレコード数と分析用 DB のレコード数が一致することを1週間モニタリングし、正しく連携できたと認識しました。
さいごに
本記事では、ジョーシスのデータ分析チームで RDS のアプリケーションデータを BigQuery にロードするアーキテクチャを紹介しました。
各 AWS サービスの選定にあたり、思っていたよりも多くの選択肢があったため、最適なサービスの組み合わせを考える点が難しかったです。
なお、ラクスルグループでは AWS インフラはグループ全体のインフラチームが担当しています。各サービスの設定を実際にしていただいたのはインフラチームの皆さんで、アーキテクチャを決定する際もたくさんの助言をいただきました。