この記事はRAKSUL Advent Calendar 2022の11日目です! qiita.com
はじめに
ラクスル22新卒エンジニアの7名はアマゾンウェブサービスジャパン合同会社様が主宰する研修「AWS JumpStart for NewGrads」に参加しました。この研修にはWeb系・ゲーム系など様々な業界の新卒エンジニアが250名以上参加し、AWSサービスを上手に活用することを主旨としたハンズオンの受講に加えて、企業を交えたチームでアーキテクチャ設計の課題に取り組みました。
ハンズオンの内容や、アーキテクチャ設計の成果物として作成したインフラ構成図をいくつか紹介したうえで、この研修でラクスルの新卒エンジニアが学んだことを紹介します!
事前学習とハンズオン
今回の研修では、事前学習コンテンツとして動画教材が用意されており、参加者は各種AWSサービスの概要や、アーキテクティングで意識するべきポイント、ユースケースに応じたアーキテクチャの構成例などについて学ぶことができました。
また研修の中では、以下の2つのハンズオンが行われました。
- スケーラブルウェブサイトハンズオン
- ALB - EC2 - RDSで可用性の高いWordPressの構成を作る
- サーバーレスハンズオン
- API Gateway - Lambda - DynamoDBを用いたサーバレスなAPIを作る
ハンズオンではチームごとにデモ環境を用意して頂き、AWSのリソースを利用したサービスの構築を体験できました。
知識として知っていたAWSサービスや構成の挙動を、実際に手を動かして確かめることができ、アーキテクチャ設計の課題に取り組む上でもイメージが湧きやすくなったと感じました。
アーキテクチャ設計課題
3日間の研修のうちほとんどの時間は、アーキテクチャ設計の課題にチームで取り組みました。 この課題は「大規模チャットサービスを作る」というお題が与えられ、それを実現するためのインフラ構成図を作成するというものです。 大量のアクセスを捌き、安定的にチャットサービスの機能を提供するためにはどのようなインフラが必要か、それを白紙から設計する難易度の高いものでした。
ここで、新卒メンバー3人にそれぞれのチームで作成した構成図を紹介してもらいましょう。
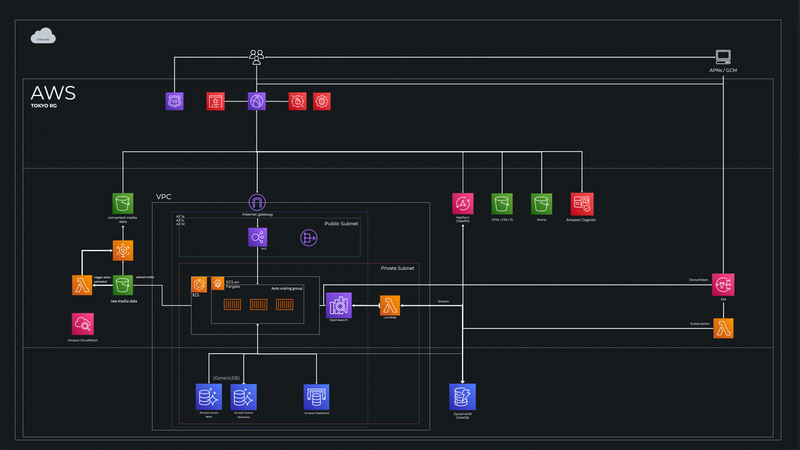
構成図1 (m.iimori)
私たちのチームで特にこだわった点は、チャット機能とそれ以外の機能を切り分けて設計した点です。今回のお題では、チャット機能は高トラフィックに耐えうる構成が必要でした。そこで、私達のチームではチャット機能をAWS AppSyncとDynamoDBを使用して設計しました。AppSyncは自動スケーリングの管理などをフルマネージドで利用できるので、高トラフィックなチャット機能でも問題なく使用できると考えました。また、AppSyncのサブスクリプション機能を使うことで、websocketによるリアルタイム通信が行えます。これもチャット機能を開発する上で非常に有用だと考えました。そして、チャット情報の読み書きを高速にするため、データベースはDynamoDBを使用しました。
チャット機能以外の部分は、ECS on FargateとAuroraを使った構成にしました。こちらはチャット機能よりは高可用性を求められることはなかったので、コンテナベースで比較的運用のしやすい構成にしました。
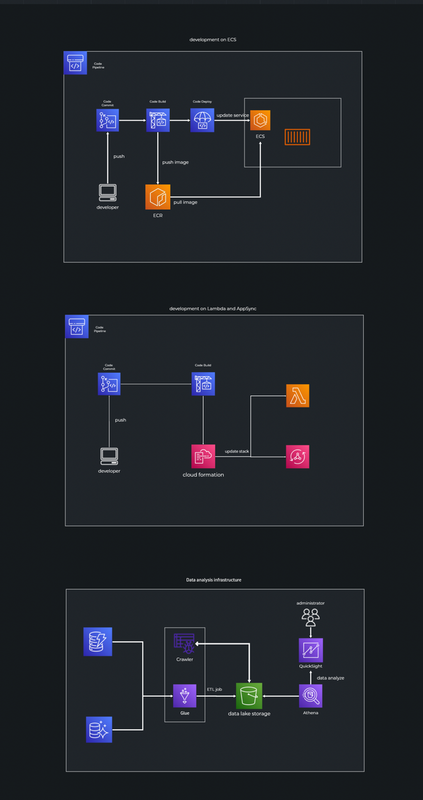
また、運用のしやすさを考えるために、デプロイのフローまで設計しました。ECSベースの部分は、CodeBuildでコンテナイメージを更新し、ECSでその最新のイメージを使う形でデプロイする仕組みを考えました。AppSyncの部分は、変更があったときにCloudFormationで最新のスタックへと更新することができます。
今回私たちのチームではマネージドサービスを多く利用して設計しました。しかし、この構成が最適かどうかは実際に構築して運用してみないことには判断できないと思います。そのため多くのサービスの特徴を知りつつ、実際に触る機会を増やしていきたいと思いました。
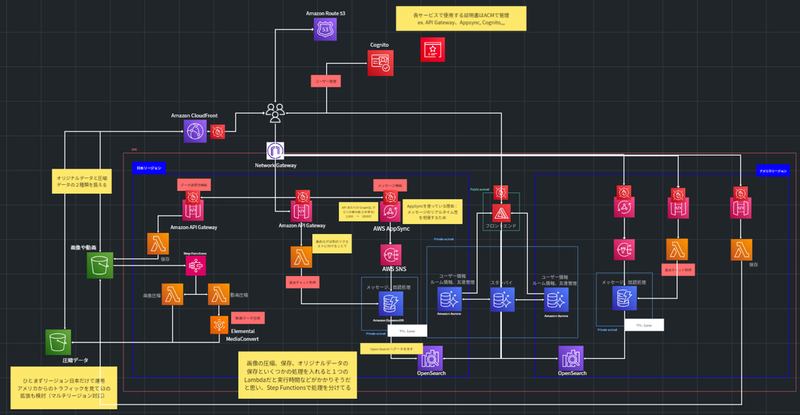
構成図2 (r.katsumata)
私たちのチームでは、開発運用コストを減らすことを最重要視し、サーバーレスサービスで実現するインフラ構成を考案しました。課題が大規模なチャットサービスのアーキテクチャを考えるということで、はじめに月のアクティブユーザーやリクエスト数を洗い出すところから議論しました。
特に工夫したのはデータ送受信の部分です。 ユーザーから画像や動画が送信されたらAPI GatewayでPOSTリクエストを受け付け、画像保存の命令がLambdaで走り、データの実体は直接S3に保存されます。 受信側は保存操作のときのみオリジナルデータか加工済みデータかを選択できるようにしたかったので、加工時に複数の処理をLambdaに持たせるのではなく、Step Functionsを挟むことで枝分かれしたLambdaが画像と動画それぞれの圧縮の命令処理をしてElemental MediaConvertで動画圧縮をおこなうようにしました。 Lambdaの処理を切り分ける点については、SA(ソリューションアーキテクト)の方に相談したところ、自分たちの候補に全くあがっていなかったStep Functionsを提案していただきました。 結果的に、この部分が他チームにはない工夫点となりました。
コンテナなしのシンプルな設計のため、信頼性や運用面の観点で安定的に機能する設計が検討できたのではないかと思います。一方でコストの最適化や拡張性を考えたインフラ設計などまだまだ改善余地がありそうなので、今回の研修を生かし今後もAWSのさまざまなサービスに触れてみたいです!
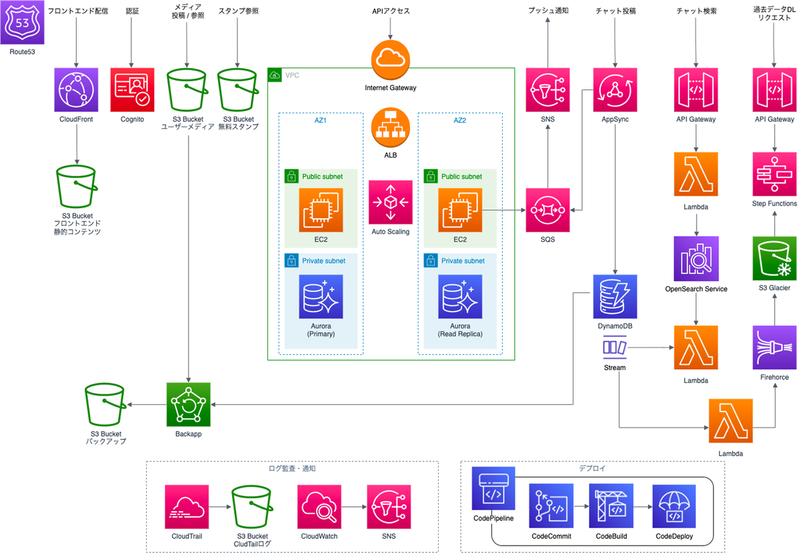
構成図3 (w.haibara)
私のチームでは、EC2上でWebアプリケーション本体を動かすことを前提として、特定の機能をそこから切り出し、部分的にサーバーレスアーキテクチャを採用しました。具体的にはチャット投稿・チャット検索・過去データ(チャット履歴)ダウンロード機能は、アプリケーション本体から切り出しています。高トラフィックなチャット投稿はAppSyncでアクセスを受け、DB負荷が高いチャット検索はOpenSearch Serviceを利用することで、アプリケーション本体のEC2・Auroraへの負荷を軽減することを狙いました。
また、過去データダウンロード機能は、最も工夫した設計になっています。 まず、AppSyncで受けたチャット投稿はDynamoDBへと保存するようになっていますが、コスト削減の観点から古い投稿データはS3にアーカイブしていくことにしました。 アーカイブされた投稿データは、ユーザーから見えなくなりますが、過去データダウンロード機能によって入手できます。 この機能を設計するにあたって論点になったのは、S3のストレージクラスです。 アーカイブされたデータは長期にわたって保存する必要があるため、ストレージクラスによってS3の累計料金が大きく変わります。 例えばS3 Glacier Deep ArchiveはGBあたりのストレージ料金が低額ですが、データの取り出しは12時間以内となっており、即座にダウンロードすることはできません。 一方でS3 Glacier Instant Retrievalなどのストレージクラスではミリ秒単位でデータを取り出すことができますが、ストレージ料金はやはりDeep Archiveの方が低額です*1。
チームで議論した結果、ストレージクラスにはDeep Archiveを選択することにしました。そのため、S3からのデータ取り出しが完了した際にそのデータを添付したメールを送付するアプリケーションが必要になりました。構成図ではStepFunctionのアイコンしかありませんが、ここでS3へのデータ取り出しのリクエスト・データ取り出しジョブの待機・ユーザーへのメール送付のロジックを持たせることになります。この設計では、データ取り出しに関する開発工数が必要なうえ、過去データを即座にダウンロードできないという点でユーザビリティも高くはありません。しかしそれ以上に大きなコストメリットが得られるのではないかと判断しました。この機能の設計を通して、開発工数・サービスレベル・コストなど多角的な観点からアーキテクチャを考える経験を得られました。
おわりに
今回の研修では、全体を通してアーキテクチャ設計の際に考えるべきポイントを学びました。今後の開発では、アーキテクチャ設計をリードしていきたいと思います。
また、設計した概念的なアーキテクチャを具体的なサービスへ対応させ、予算を見立てることも行いました。実際にサービスを開発する際に、適切なサービスを要件と照らし合わせて選択し、ビジネス課題の解決を目指していきます。
ラクスルでは、このAWS研修のようにエンジニアの成長機会が数多く用意されており、他にも多様な制度を通じてエンジニアの学習を支援しています。ラクスルで一緒に働いてみたいと思った方はこちらのページをチェックしてみてください!