
この記事は、ノバセル - Qiita Advent Calendar 2024 - Qiita の 5日目の記事です。
昨日は Model Context Protocol(MCP)からみたLLMの進化とマーケティング関連作業の近未来 - RAKSUL TechBlog という記事でした。
はじめに
こんにちは、ノバセルでデータエンジニアをしている森田 (@kz_morita) です。 先日開催された「RAKSUL × primeNumber 合同勉強会」で、「BI ダッシュボードの DevOps と CI/CD についての取り組みと課題」をテーマに登壇しました。
開催レポートはこちらになります。
本記事では、さらに深掘りして QuickSight を用いたダッシュボードの継続的なデリバリーを実現するための取り組みとその課題について紹介します。
背景と課題
ノバセルでは、データを収集・分析・可視化を行うダッシュボードを構築しています。 このダッシュボードは価値検証のために素早く開発し利用者からのフィードバックを受けながら改善をし続けていきたいという要件がありました。
既存の BI tool を用いてダッシュボードを作成する場合提供スピードはあがりますが、一方で継続的にデリバリーすることが難しいという課題を感じています。 例えば一度作成したダッシュボードに対して変更を与えたい時、BI tool が提供する編集画面で修正を行うと、利用者が閲覧している画面に即時反映されてしまうケースが多いです。
そのため、ダッシュボードのリリース方法を工夫しなければならずリリースされたダッシュボードに影響を与えないよう慎重に開発したり、ある程度のまとまりが完成するまでリリースができなかったりという課題が発生します。 この課題は細かくすばやくデプロイをすることを難しくし、ダッシュボード開発の生産性に悪い影響を及ぼすと考えています。
これらの課題を解消するため、ソフトウェア開発で用いられる継続的デリバリーをダッシュボード開発でも適用させる取り組みを行いました。
環境の分離
ソフトウェア開発では、開発環境、ステージング環境、本番環境といった形で環境を分離し開発中でも本番環境には影響を与えないプラクティスが実践されています。 ダッシュボード開発においてもこのプラクティスを適用することが継続的デリバリーの実現のための第一歩だと考えます。
そこで以下の図のようにデータとBIダッシュボード側で環境を分離するアーキテクチャにしました。
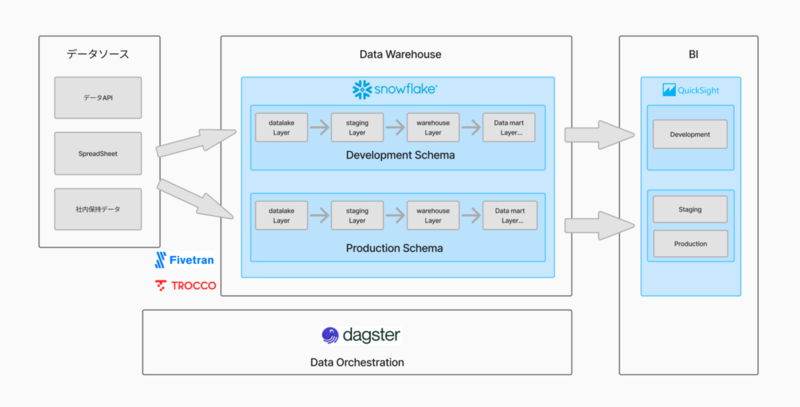
Snowflake を用いているため開発環境と本番環境を Schema で分離する構成にしています。 データモデルは、dbt で開発しており、Dagster 上で dbt によるデータ変換のパイプラインが動いています。
開発用の Schema と本番用の Schema を分ける方法ですが、Dagster の Branch Deployment 機能で実現できます。
Branch Deployments in Dagster+ | Dagster Docs
簡単に説明すると、GitHub のブランチ (Pull Request) と Dagster 上の Deployment を紐づけることができる機能です。 この機能を用いると development 用のブランチへマージすると開発用スキーマにデータモデルを反映し、main ブランチへマージすると本番用 Schema へ反映することができます。
QuickSight の環境分離
QuickSight で環境を分離する方法はいくつかありますが、フォルダベースの方法を採用しました。
QuickSight ではフォルダごとに権限管理をすることができるため、development, staging, production といったフォルダを作成しそれぞれに対して、グループ単位ごとに権限を付与しています。利用者に対しては本番環境にのみアクセスを許可し、開発者はすべての環境にアクセスできるといった具合です。
また development 環境は開発用 Schema にのみアクセスできるようにし、staging, production 環境は 本番用 Schema にのみアクセスできるようにアクセス管理を行います。
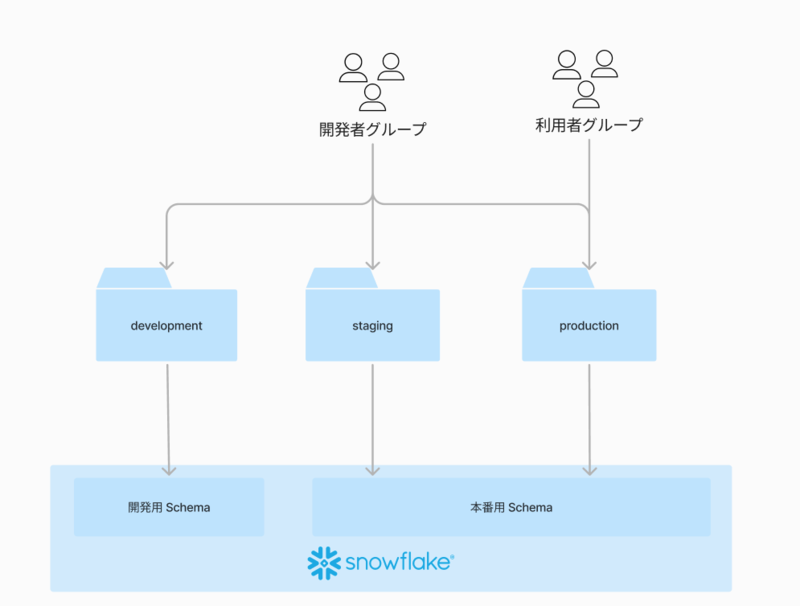
上記の構成において開発者はまず development 環境でダッシュボードを作成します。開発が完了したら staging 環境へデプロイし、本番データで確認したのち production 環境へデプロイします。 QuickSight で具体的にデプロイをする流れを示したのが以下の図になります。
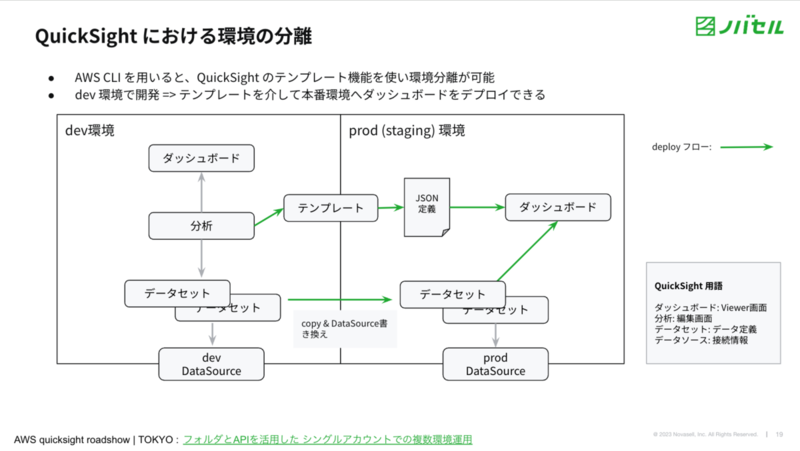
development 環境で作成したダッシュボードを staging, production 環境へデプロイするために、QuickSight のテンプレート機能を利用しています。純粋にコピーした分析から新たにダッシュボードを作成する場合、ダッシュボードのURLが都度変更されてしまいます。利用者の閲覧体験を考慮した結果テンプレート機能を利用することにしました。 ただし、テンプレート機能は GUI からは利用できないため、aws-cli などを用いた API 経由で利用する必要があります。
採用したテンプレート機能を利用したデプロイフローは以下です。
- 開発した分析、データセットのコピー
- テンプレート作成
- 作成したテンプレートを元にダッシュボード更新
データセット・分析のコピーや、テンプレートの作成、テンプレートからダッシュボードの作成など、一連の作業は aws-cli を用いて実現できます。
一例として、テンプレートを作成しダッシュボードを作成するまでのコマンドを紹介します。
まずは、既存の分析からテンプレートを作成します。
テンプレートの定義のJSONファイルです。(template-definition.json とします)
{ "SourceAnalysis": { "Arn": "arn:aws:quicksight:${REGION}:${AWS_ACCOUNT_ID}:analysis/${TARGET_ANALYSIS_ID}", "DataSetReferences": [ { "DataSetPlaceholder": "DATA_SET_1", "DataSetArn": "arn:aws:quicksight:${REGION}:${AWS_ACCOUNT_ID}:dataset/${DATA_SET_1_ID}" }, { "DataSetPlaceholder": "DATA_SET_2", "DataSetArn": "arn:aws:quicksight:${REGION}:${AWS_ACCOUNT_ID}:dataset/${DATA_SET_2_ID}" } ] } }
JSON の内容としてはコピー元の分析と、その分析が参照しているデータセットの情報を指定します。 実際にテンプレートを作成するのは以下のコマンドになります。
aws quicksight update-template \ --aws-account-id ${AWS_ACCOUNT_ID} \ --template-id ${TEMPLATE_ID} \ --source-entity file://template-definition.json
テンプレートが作れたのでこのテンプレートを用いてダッシュボードを作成します。
JSON ファイルでダッシュボードの定義をします。(dashboard-definition.json とします)
{ "SourceTemplate": { "DataSetReferences": [ { "DataSetPlaceholder": "DATA_SET_1", "DataSetArn": "arn:aws:quicksight:${REGION}:${AWS_ACCOUNT_ID}:dataset/${DATA_SET_1_FOR_PRODUCTION_ID}" }, { "DataSetPlaceholder": "DATA_SET_2", "DataSetArn": "arn:aws:quicksight:${REGION}:${AWS_ACCOUNT_ID}:dataset/${DATA_SET_2_FOR_PRODUCTION_ID}" } ], "Arn": "arn:aws:quicksight:${REGION}:${AWS_ACCOUNT_ID}:template/${TEMPLATE_ID}" } }
注目すべきは2点です。 まず前の手順で作成した テンプレートの Arn を指定することで使用したいテンプレートを選択します。 次に、DataSetReferences の部分です。DataSetPlaceHolder の名前の DataSet を別のデータセット (つまり本番のデータセット) で差し替えることができます。 そのため DataSetPlaceholder は、テンプレート作成時に指定した名前のみを指定できます。あらかじめコピーし接続先を本番 Schema を向くようにしておいたデータセットを参照することで本番用のダッシュボードを作成できます。
以下はダッシュボードの更新のためのコマンドです。
$ aws quicksight update-dashboard \ --aws-account-id ${AWS_ACCOUNT_ID} \ --dashboard-id ${DASHBOARD_ID} \ --name ${DASHBOARD_NAME} \ --source-entity file://dashboard-definition.json --version-description "${RELEASE_MESSAGE}" \
aws-cli コマンドを活用すると、このようにデプロイの一連のフローを実装することができます。
これからの課題
上記の施策を実行した結果、環境の分離を実現することができ継続的デリバリーの実現へ一歩近づくことができました。 具体的には、小さい単位でリリースを行うことができデリバリー済みのダッシュボードに対しての開発も安全に行うことができるようになりました。
ただし、下記のように残された課題もあります。
- リリースのフローが完全に自動化されていない
- ダッシュボードの画面が正しいことを保証するテストが実現できていない
特に手作業でのリリースフローは、継続的デリバリーを妨げる要因となるため改善していきます。
まとめ
本記事では、ダッシュボードの継続的デリバリーについての取り組みと課題についてご紹介させていただきました。 今回は継続的デリバリーに着目しましたが、ソフトウェアエンジニアで行われているアプローチは、データエンジニアリングの領域でも非常に生きることが多いと改めて実感しました。
アジリティと品質を高く保った開発を目指して今後も取り組んでいきます。
おわりに
明日は、CausalImpactのアンチパターン という内容の記事になる予定です。こちらもお楽しみに!