はじめに
はじめまして!ノバセル事業部 Novasell Analytics開発チームの浅田です。
先日、ラクスル23新卒エンジニアはアマゾンウェブサービスジャパン合同会社様が主宰する研修「AWS JumpStart 2023/5-6 設計編」に参加しました。このイベントに参加することで、AWSの基本的なサービスやアーキテクチャ設計のポイントを理解することができました。以下は成果物の一部です。
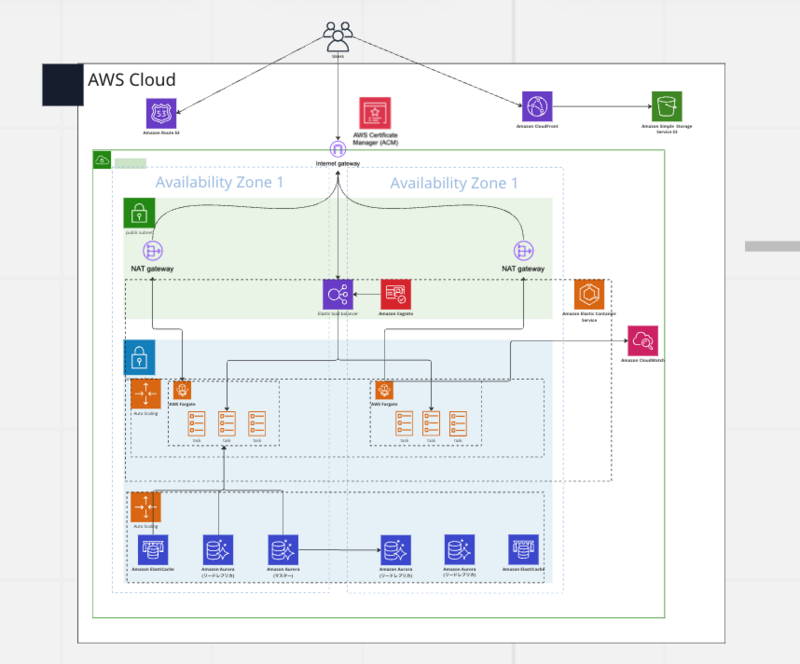
今回の記事では、実際にイベントに参加して学んだアーキテクチャ設計のポイントを概観した上で、それを意識した具体の思考実験を行いたいと思います。
ソフトウェアアーキテクチャ設計とその観点
ソフトウェアアーキテクチャ設計とは、機能・非機能要件、制約条件を満たすシステム全体の設計を、ソフトウェアだけでなくインフラの観点も含めて行うプロセスです。機能要件に関しては各サービスごとに異なりますが、非機能要件に関してはある程度一般化することができます。
非機能要件とは具体以下のような観点になります。
信頼性
スケーラビリティ・パフォーマンス
開発・運用
コスト管理
セキュリティ
以下ではそれぞれの観点を概観していきたいと思います。
信頼性
信頼性とは、あるサービスが停止することなく正常に動作し続けるかどうかという観点です。どれだけの信頼性を担保すべきかはビジネス判断になりますが、一般的には次のような手法で高めることができます。
- ロードバランサ: 負荷を複数のサーバーに分散することで、特定のサーバーがダウンした場合もサービスを継続させることができます。また、ロードバランサ自体も裏側で冗長化することで、サービスの信頼性を高めます。
- DBレプリケーション: データベースをリアルタイムで複製し、プライマリデータベースがダウンした場合もフェールオーバー(切り替え)することでサービスを継続することができます。
- バックアップ戦略: データのロスを防ぐために、定期的なバックアップを実施します。
スケーラビリティ・パフォーマンス
ユーザーが増えたときでも、サービスの品質を維持するためには、スケーラビリティとパフォーマンスを保証する必要があります。以下に具体のアプローチを示します。
- サーバー: ロードバランサと組み合わせ、スケールアップとスケールアウトを行うことで、パフォーマンスを向上させます。
- DB: リードレプリカを使用して、読み込み負荷を軽減します。また、高速なデータのやり取りが可能なインメモリデータストア(Redisなど)を使用して、頻繁にアクセスするデータをキャッシュ化します。
- 静的コンテンツ配信: CDNを使用してコンテンツのキャッシュを作成し、オブジェクトストレージ(S3など)を用いて大規模なデータを保存・配信します。
開発・運用
システムの開発と運用の効率を向上させるためには、以下のような観点が重要です。
- ログの収集・分析: メトリクスやログを収集・分析する仕組みを整備し、ダッシュボードを用いて可視化します。
- デプロイ: CI/CDの仕組みを用意し、自動化を進めます。
- インフラのコード化: IaCを利用して、インフラの状態をコードで管理します。
- マネージドサービスの利用: 構築・運用作業をAWSなどのマネージドサービスに任せることで、運用負荷を軽減します。ただし、これはコストの観点とのトレードオフでもあります。
コスト管理について
コスト管理は常に他の観点とのトレードオフになる重要な要素です。以下にその主なポイントを記述します。
コストの概算と内訳の理解: 前提として、コストの概算とその内訳を理解することがなにより重要です。これにより、コストのどの部分が高く、どこを改善すればコスト削減が可能かが見えるようになります。
ビジネスの成功を目指す: 最終的にはビジネスの成功が目標です。過度にコスト削減を実現した結果他の要件を満たせずビジネスが失敗するというシナリオは本末転倒なので、コストは常に他の観点とのトレードオフであることを意識する必要があります。また全体的なコスト概算だけでなく、その中で大きなウェイトを占める要素の特定も重要です。例えば、サーバーとDBが大きな割合を占めている場合には以下のような2つの対策をとることが考えられます。
リソースの選択: 適切なリソースのサイズやタイプを選択しなければ、無駄なコストが発生します。適切なリソース選択によりコスト削減が可能となります。
サーバーの稼働状況: リクエストが少ない時間でも多数のサーバーが動作していると、無駄なコストが発生します。AutoScalingの機能を利用することで、需要に応じてサーバーの数を自動調整し、コスト効率の良い運用が可能になります。
セキュリティ
リスク分析 まずはリスク分析から始めるべきです。何を、そしてどの程度まで保護する必要があるのかを明確にします。
ベースラインアプローチ ベースラインアプローチはチェックリスト型のアプローチで、AWSの「Well Architected Framework」などが参考になります。この方法はすぐに取り組むことが可能ですが、一方で汎用的なアプローチとなるため、特定の要件に対するカスタム対応が難しいという欠点もあります。
詳細なリスク分析 詳細なリスク分析ではまず自分たちのシステムや情報の状況を深く理解した上で、どの情報やシステムを保護するべきかその情報が漏洩したりシステムが停止した場合にどのようなインパクトが生じるかを理解し、それらを防止するための対策を考えます。そして、現状の予算内でどの程度までの対策を施すことが可能かを決定します。
これらのステップにより、セキュリティ対策を効果的に実行することが可能になります。
具体思考実験「Lambda vs Glue」
ここからは、上で概観した観点を意識しながら実験的に具体のアーキテクチャ検討を行ってみたいと思います。
ここでは以下のような問いを設定します。
「Amazon RDSにあるデータをAmazon S3にコピーしたい場合、どのようなサービスを使うのが適切か?」
上記の要件に関しては、いろいろなアプローチを取り得ますが、ここではより問題をわかりやすくするために想定サービスをLambdaとGlueに絞った上で、両者を特に上の4つの観点(信頼性、スケーラビリティ・パフォーマンス、開発・運用、コスト)から比較検討していきたいと思います。
以下、簡単な頭出しになります。

信頼性
Lambda
- 信頼性: Lambdaは高い信頼性を有しています。システムは自動的に冗長性を保ち、関数が複数のアベイラビリティーゾーン(AZ)で実行されるため、単一の障害点が存在しません。
- 制限: しかし、Lambdaには実行時間の制限(最大15分)があるため、大量のデータを一度に移動する作業には向いていません。また、再試行ポリシーは自分で設定しなければならないという点も考慮する必要があります。
Glue
- 信頼性: Glueは大規模なETL(Extract, Transform, Load)タスクを処理するために設計されており、大量のデータをRDSからS3に移動する必要がある場合、Glueはこのタスクを一貫性をもって処理できます。
- 自動再試行: Glueジョブは自動的に再試行が行われ、タイムアウトも自由に設定することができます。
スケーラビリティ・パフォーマンス
Lambda
スケーラビリティ: Lambdaはスケーラブルなサービスで、自動的にスケーリングされます。ただし、その一方でLambdaは同時実行数に制限があり、それに加えて、各関数の最大実行時間は15分に制限されています。したがって、大量のデータを一度に処理する必要がある場合や、長時間実行する必要があるタスクに対しては、スケーラビリティが制限されうると言えます。
パフォーマンス: Lambdaは、特定のトリガーに応じてリアルタイムでレスポンスを返す能力に優れています。一方で、大規模なデータ移動や大量のデータの処理に対するパフォーマンスは、処理時間の制限や同時実行数の制限などの要因により制約される可能性があります。
Glue
スケーラビリティ: Glueは大規模なETL作業のために設計されており、必要に応じてジョブを自動的にスケーリングする能力があります。これにより、大量のデータを効率的に一度に処理することが可能です。
パフォーマンス: GlueはApache Sparkを基盤にした分散データ処理エンジンを利用しているため、大規模なデータ処理に対するパフォーマンスは非常に高いです。
開発と運用
Lambda
開発: プログラミング言語の選択肢が多く、既存のコードベースを利用することが可能です。しかし、ETLワークロードのような大規模なデータ処理を行う場合、それぞれの関数を適切に設計し、データの一貫性を保つための追加のロジックが必要になる可能性があります。
運用: 一度デプロイされた関数は、定義したトリガーによって自動的に実行されます。しかし、データ移動の失敗やエラーハンドリングについては、自分で実装する必要があります。
Glue
開発: Glueでは、視覚的なインターフェースを用いてETLジョブを設計し、データ移動と変換のロジックを定義することができます。
運用: 自動的なスケーリング、失敗時の再試行、エラーロギングなど、必要な運用機能がデフォルトで組み込まれています。しかし、Glueジョブのデバッグや最適化には、Apache Sparkなどに関する知識が必要となる場合があります。
コスト
Lambda
AWS Lambdaのコストは、実行時間とリクエスト数に基づいて計算されます。つまり、関数が実行されない時間には費用が発生しません。しかし、裏を返すと関数の実行時間が長い、または大量のリクエストを処理する必要がある場合、コストは急速に増加するとも言えます。
Glue
AWS Glueのコストは、実行時間と使用したデータ処理ユニット(DPU)に基づいて計算されます。つまり、大量のデータを一度に処理するようなケースではコストが跳ね上がると言えます。ただし、Glueは大規模データを処理する能力が高いので結果的にコストパフォーマンスは良いといえます。
まとめ
具体、どちらを選択すべきかに関しては、機能要件とも密接に関連するところではあるので明言はできませんが、上記の検討から一般的に以下のようなプラクティスが得られました。
大量のデータを一度に移動するという場合においては、AWS Glueに軍配があがる。一方でリアルタイムのレスポンスや特定のトリガーに応じた小規模なタスクについては、AWS Lambdaが適している。
まとめのまとめ: アーキテクチャ設計の進め方
この記事では、アーキテクチャ設計において意識すべきポイントを概観した上で、具体の検討を行いました。
アーキテクチャ設計においては、大前提機能要件と非機能要件の両方を考慮する必要があります。当然すべての要件や制約を満たすのは難しいですが、その場合はビジネスを成功させるために最も優先すべき観点を意識し、トレードオフを判断しましょう。