はじめに
ラクスルグループのノバセルで新卒2年目のエンジニアをしています田村(tamtam)です💪
現在は、データサイエンティストが作成した学習済みモデルをもとに、推論を行うロジックを実装し、Web APIとして提供するための開発をしています。
この記事を読んで得られること
この記事では、推論用REST APIサーバーを構築する際に考えたことを2つのセクションに分けて紹介します。
- 推論用サーバーを構成するAWSリソースの検討
- 推論コードを実装する上での検討
SageMakerを利用し推論用REST APIサーバーを構築する方の参考になれればと思います!
それでは詳細について見ていきましょう!
参考となるレポジトリ
今回の記事に際して、参考となるプロジェクトテンプレートを共有します。
上記のテンプレートは、サンプルとしてWord2Vecを利用した予測を行います。試したい方はTesting Production Image Locallyを参照ください。
1.推論用サーバーを構成するAWSリソースの検討
定期的に学習済みモデルを更新し、デプロイするフローの構築を想定したサービスの検討
今回は、1〜2週間ごとに学習済みモデルを更新し、デプロイするサービスを想定します。
初期段階では、手動でモデルの学習を行い、推論サーバーのみ提供を考えています。しかし、将来の効率化を見据えて、モデルの定期更新とデプロイの自動化を検討しています。
上記のことを踏まえ、機械学習モデルを構築からデプロイまで行うサービスであるSageMakerを選択しました。
※ AWS外のサービスだとDatabricksも学習や推論を効率的に行う上で良い選択になると考えます。
REST APIで提供することを想定したSageMakerのタイプの選定
今回は社内の多様なサービスから容易に接続するため、推論サーバーはREST APIとして提供する方針にしました。
SageMakerの選択肢の中では、リアルタイム推論やサーバーレス推論が同期処理を可能にするため、これらを優先的に検討しています。
SageMakerのタイプの大まかな選定に関しては、Amazon SageMaker 推論 Part1 推論の頻出課題とSageMakerによる 解決方法がわかりやすいです。

加えてREST APIとして提供する際には、API Gatewayのマッピングテンプレートを使うことでLambdaを間に挟まずSageMakerと連携することができます。
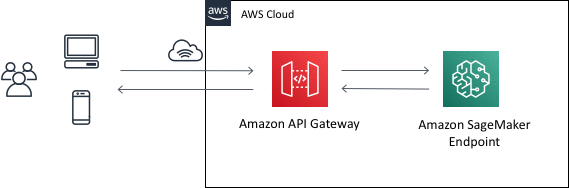
今回の要件では上記の実装で問題なかったため採用する方針になりました。
推論の粒度を考慮
上記のようにAPI Gatewayを利用する場合、API Gatewayのタイムアウト制限を考慮する必要があります。 (API GatewayのREST APIタイプに関するクォータによると、統合のタイムアウトの最大時間は29秒です。)
例えば、バッチ変換による推論のように、大量のデータで一度に行おうとします。その際、処理時間が長くAPI Gatewayのタイムアウト制限に達した場合、HTTP 408 Request Timeoutを返してしまうことがあると考えます。
この問題を回避するために、1度の推論を1つのデータに限定する、あるいは推論のリミットを設定するなどの対応が必要と思われます。
特に2023年8月16日の情報では、サーバーレス推論を利用する場合、GPUインスタンスが使用できないためCPUでの推論となります。そのため処理時間を意識した設計がより一層必要になることを考えます。
こういった制限を考慮して、上記のような推論粒度の調整やそもそものSageMakerのタイプの吟味が必要となるでしょう。
2.推論コードを実装する上での検討
データサイエンティストが既に用意したコードを移植するためのコンテナ環境の検討
今回は、データサイエンティストがGoogleColab上で検証した推論コードを、SageMaker上に移植することを想定しました。
その中で、使用するライブラリやコードに関しては、移植時にそのまま移すことを想定し、以下のカスタムコンテナ実装パターンの4パターン目を採用しました。こちらはスクラッチで独自の推論コードを実行するパターンです。
また、具体的な実装にあたっては以下のレポジトリを参考にしました。
独自の推論コードで気にするところ
上記の記事に書いてある内容が全てですが、ここでは最低限押さえるべき箇所をピックアップして紹介します。
前述したプロジェクトテンプレートではこうした要件を満たすように実装しています。
推論イメージの実行
コンテナ起動時に、コマンドにserveを指定します。
docker run image serve
もしserveコマンド以外で実行した場合はENTRYPOINTをDockerfileに指定する必要があります。
モデルアーティファクトのロード
コンテナ起動時に、予めSageMakerのモデル作成時に指定したS3 - tar.gz アーカイブを、 /opt/ml/model に展開します。
コンテナがリクエストを提供する方法
コンテナにはポート 8080の /invocations と /pingに応答するウェブサーバーを実装します。
FastAPIの利用
AWSのSampleではFlaskを利用していますが、今回はFastAPIを採用しました。
FastAPIはASGI (Asynchronous Server Gateway Interface) 標準のStarletteをベースに実装されており、非同期I/Oをサポートします。
また、Pydanticと連携しリクエスト/レスポンスをはじめとする型ヒント(型のバリデーション)をサポートしています。
そのほか、ドキュメントの自動生成なども対応していることから、実行パフォーマンスだけでなく開発生産性の向上にも寄与するモノとなっています。
FastAPIを用いた開発に関しては、手前味噌ですが以前投稿した記事も読むと良いかもしれません。 techblog.raksul.com
マルチステージビルドの利用
前述したプロジェクトテンプレートでは、Poetryを依存関係の管理に利用しています。
このことから、FastAPIの公式のドキュメントを参考に、マルチステージビルドを採用することにしました。
FROM python:3.10 as requirements-stage WORKDIR /tmp RUN pip install poetry==1.5.1 COPY ./pyproject.toml ./poetry.lock* /tmp/ RUN poetry export -f requirements.txt --output requirements.txt --without-hashes FROM python:3.10 RUN apt-get -y update && apt-get install -y --no-install-recommends \ g++ \ make \ cmake \ wget \ nginx \ ca-certificates \ && rm -rf /var/lib/apt/lists/* RUN ln -s /usr/bin/python3 /usr/bin/python & \ ln -s /usr/bin/pip3 /usr/bin/pip ENV PATH="/opt/program:${PATH}" ENV BASE_DIR="/opt/" ENV PYTHONPATH="/opt/" COPY --from=requirements-stage /tmp/requirements.txt /requirements.txt RUN pip install -r requirements.txt COPY ./opt/ /opt/ RUN chmod 755 /opt/program/serve EXPOSE 8080
本番運用する上でのスタック
Workerの利用
FastAPIはASGI標準であるため、Uvicornのようなサーバーを用いて単一のプロセスで処理します。
しかし、アプリケーションをデプロイする際には、多くのリクエストを処理を捌くために、複数のコアを利用しプロセスのレプリケーションを行うことを考えます。
FastAPIを利用する場合、FastAPIはWSGI標準ではないため、サンプルで示されるようなGunicornを直接使うことができません。
そのため、Gunicornをプロセスマネージャーとし、複数のUvicornのワーカーを管理して複数のプロセスを起動させるような対応を行います。(参考: Server Workers - Gunicorn と Uvicorn)
なお、UvicornとGunicornの連携によるWorkerの利用は必ずしも最適ではないので、ユースケースに応じて選択しましょう。(参考: レプリケーション - プロセス数)
Nginxの利用
今回は同一コンテナ上にNginxを設けるようにしています。
Nginxはロードバランシング、キャッシング、SSL Termination、やリクエスト処理機能を提供します。
餅は餅屋の精神で、本番環境ではUvicornやGunicornよりも上位の処理をNginxといった専用のミドルウェアに任せ、組み合わせて利用することが推奨されています。
以下の2つの内容が参考になると思われます。 docs.gunicorn.org
まとめの今後の展望
この記事では、推論用REST APIサーバーを構築する際に考えたことを2つのセクションに分けて紹介していきました。
- 推論用サーバーを構成するAWSリソースの検討
- 推論コードを実装する上での検討
今回は推論コードや学習済みモデルをデプロイしエンドポイントを更新するまでのフローについては触れていません。次回機会があれば書きたいと考えています!