こんにちは。ハコベル事業本部 ソリューションチームの丸山です。RAKSUL Advent Calendar 2021 17日目の記事になります。 現在はハコベルコネクトという物流における配車業務のデジタル化により、業務自動化・情報一元化を行い、顧客の業務コスト削減を図るサービスの開発をしています。
ハコベルコネクトでは11月にDocker + Fastify + webpack-dev-server(Vue CLI)という構成でフロントエンドの開発環境とシステム構成の刷新を行いました。 Nuxt.jsやNext.jsといったフレームワークを使用することも検討しましたが、永く運用してきたプロダクトなためいきなり乗り換えることは難しく、悩んだ結果上記のような構成にしています。 同じような悩みを持った方に少しでも参考になればと思い、どのような構成・実装を行なっているのか紹介します。
背景
まず初めにフロントエンド環境を刷新するに至った経緯についてですが、ハコベルコネクトはプロダクト立ち上げ時にはRuby on Railsによってフロントエンドからバックエンドまでを実装したモノリシックな構成となっていました。 その後、開発を続けるうちにコードベースも大きくなり、Railsのviewだけではフロントエンドの開発を継続するのが難しくなってきたためVue.jsを使用しRailsからは切り離した構成へと変更しました。 しかし、完全なSPA化などには至っておらず、またページアクセスの際のルーティングやアセットの配信などは引き続きRailsを使用しており、Gitリポジトリとしても1つのリポジトリに全てが入った状態となっていました。
永らくその状態で運用されていたのですが、フロントエンドとバックエンドが同じリポジトリにあることで、どちらかの変更しかしていなくてもデプロイ時に全体のビルドが行われてしまい時間がかかっていたことや、開発環境やライブラリの変更を行う際に必要以上に影響範囲を気にしなくてはならないなどの問題が発生していました。
そこで、リポジトリをフロントエンド用とバックエンド用に分け、ページのルーティングやアセットの配信もフロントエンド側で行うようにすることで、RailsはAPIサーバとしての責務に集中しお互いを疎結合にすることを目的としてフロントエンド開発環境の刷新を行いました。
構成
まず初めに考えたのはフロントエンド環境を完全にSPA化し、Nuxt.jsなどを使用してフロントエンドサーバを構築することでした。しかし、ページごとにエントリポイントがあり、それぞれを別ファイルとしてビルドしている現状から、限られた時間やリソースの中でその状態まで一気に対応することは難しいという結論に至りました。 そこで、まずはリポジトリを分割することとルーティングなどのフロントエンドの責務をバックエンドから引き剥がすことを第一として既存のVueのコードベースやビルドフローにはできる限り変更を加えない方法をとることにしました。
最終的な開発環境の構成は以下
- Vue部分はこれまで通りページごとのエントリポイントを持ち、開発中はwebpack-dev-server(Vue CLI)を使用する
- ページのルーティングにはFastifyを使用。本番環境ではアセットの配信も行うが開発中はwebpack-dev-serverが行う
- ローカルでの開発環境はdocker-composeを用い、webpack-dev-server とFastifyへの振り分けにはnginx-proxyイメージを使用する
- ローカルでhttpsでのアクセスが必要な場合には https-portalイメージを使用
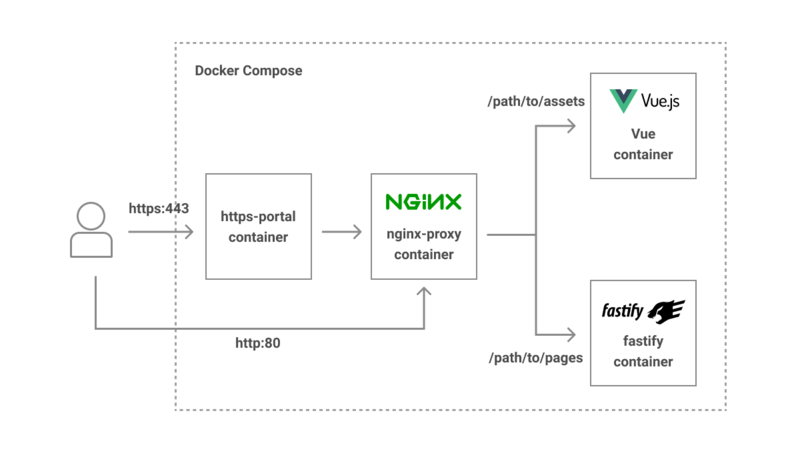
docker-compose.ymlのサンプルは以下のようになります。(説明用のためいくつかの設定は省略しています)
version: '3'
services:
https-portal:
profiles:
- https
image: steveltn/https-portal:latest
ports:
- 8443:443
environment:
STAGE: local
DOMAINS: 'localhost -> http://nginx-proxy:80'
nginx-proxy:
image: jwilder/nginx-proxy:0.9.0
ports:
- 8080:80
volumes:
- /var/run/docker.sock:/tmp/docker.sock:ro
- ./dev-proxy:/etc/nginx/vhost.d
depends_on:
- vue
- fastify
vue:
build: ./vue
hostname: vue
environment:
VIRTUAL_HOST: vue.local
VIRTUAL_PORT: 8080
volumes:
- ./vue:/app:delegated
-/app/node_modules
command: "yarn dev"
fastify:
build: ./fastify
environment:
VIRTUAL_HOST: localhost
VIRTUAL_PORT: 80
volumes:
- ./fastify:/app:delegated
-/app/node_modules
command: "dockerize -wait http://vue:8080/webpack-dev-server -timeout 10m -wait-retry-interval 5s yarn serve"
ポイント
上記構成のポイントをいくつかご紹介します。
nginx-proxy
Docker Hub にて公開されているDocker image です。
nginxのリバースプロキシを構成し、複数コンテナ間のアクセス振り分けなどを簡単に設定することができます。
各serviceのenvironmentに VIRTUAL_HOST VIRTUAL_PORT を指定するとその VIRTUAL_HOST でnginx-proxyコンテナにアクセスがあった際に各serviceの VIRTUAL_PORT で指定したportへアクセスを振り分けてくれます。
services:
nginx-proxy:
ports:
- 8080:80
vue:
environment:
VIRTUAL_HOST: vue.local
VIRTUAL_PORT: 8080
fastify
environment:
VIRTUAL_HOST: localhost
VIRTUAL_PORT: 80
これで http://localhost:8080 へアクセスすることで nginx-proxyコンテナがfastifyコンテナの80番ポートへとアクセスを振り分けてくれます。
ただしjsファイルなどのアセットはvueコンテナよりwebpack-dev-serverから配信を行うため、vueコンテナへと振り分けを行う必要があります。
そこで /dev-proxy ディレクトリ内に localhost というファイルを作り、nginxのlocation設定を記述します。
# docker-compose.yml
version: '3'
services:
nginx-proxy:
volumes:
- ./dev-proxy:/etc/nginx/vhost.d # ./dev-proxy内のファイルをマウントする
# /dev-proxy/localhost
location ~ ^/(assets/.*) {
proxy_pass http://vue.local/$1;
}
これで、 http://localhost:8080/assets 配下へのアクセスはvueコンテナへと振り分けられます。
また、以下のような記述も追加することで、 http://localhost:8080/_vue 配下へのアクセスはvueコンテナへと振り分けられるようになり、アセットファイルのパスや内容を調査したい時にデバッグがしやすくなり便利です。
# /dev-proxy/localhost
location ~ ^/_vue/(.*) {
proxy_pass http://vue.local/$1;
}
https-portal
こちらも Docker Hub にて公開されているDocker imageです。 nginx, Let's Encrypt を使用してHTTPSサーバーを立ち上げることができます。 https環境を使用する必要がある場合のために使用しています。
# docker-compose.yml
services:
https-portal:
profiles:
- https
image: steveltn/https-portal:latest
ports:
- 8443:443
environment:
STAGE: local
DOMAINS: 'localhost -> http://nginx-proxy:80'
nginx-proxy:
image: jwilder/nginx-proxy:0.9.0
このように設定することで、 https://localhost:8443 へのアクセスをnginx-proxyコンテナに振り分けることができ、自動でLet's EncryptよりSSL証明書を取得してくれます。
また、httpsでの挙動確認などが必要な場面は限られるため、常にhttps-portalコンテナを立ち上げておく必要はありません。
そのため profiles: https という値を設定しておくことで、docker-composeの立ち上げ時に --profile https というオプションを指定した時のみ起動するようにしています。
dockerize
https://github.com/jwilder/dockerize
他のコンテナの起動を待つために使用しているツールです。
vueコンテナ内ではビルド時にwebpack-manifest-plugin を使用しているため、fastifyコンテナの起動時に各ページで読み込むjsのエントリポイントを決める際にvueコンテナの manifest.json を参照する必要があります。
そのため、fastifyコンテナの起動はvueコンテナの起動を待ってから行う必要があり、それを実現するために dockerize を使用しました。
まずfastifyコンテナのDockerfile内で dockerize をインストールします。
# /fastify/Dockerfile ENV DOCKERIZE_VERSION v0.6.1 RUN wget https://github.com/jwilder/dockerize/releases/download/$DOCKERIZE_VERSION/dockerize-linux-amd64-$DOCKERIZE_VERSION.tar.gz \ && tar -C /usr/local/bin -xzvf dockerize-linux-amd64-$DOCKERIZE_VERSION.tar.gz \ && rm dockerize-linux-amd64-$DOCKERIZE_VERSION.tar.gz
そしてdocker-compose.yml内のcommandでdockerizeを使用するようにします。
# docker-compose.yml
services:
fastify:
command: "dockerize -wait http://vue:8080/webpack-dev-server -timeout 10m -wait-retry-interval 5s yarn serve"
このように記述することでfastifyコンテナは http://vue:8080/webpack-dev-server へのアクセスを試み、成功すれば起動するようになります。
アクセスに失敗した場合には5秒おきにリトライを行い成功するまで待つことができるようになります。
実際に使用する際にはリトライ間隔はdocker-compose起動時に引数として指定できるようにしておくと良いかと思います。
最後に
このようにして、フロントエンドの開発環境を全てdocker-composeの中にまとめることでき、1つのコマンドで依存関係のダウンロードからサーバの起動までをローカル環境を汚さずに行えるようになりました。
気をつけたい点として、vueコンテナに関してはビルドのリソース消費が大きく、またコンテナにマウントするファイルの数も多くなりがちなので、マシンスペックやプロジェクトの規模によってはビルドに非常に時間がかかるようになってしまう場合もあるでしょう。 その場合はvueコンテナはDockerコンテナでのビルドは行わずにローカルで起動させ、ローカルサーバに向けてnginx-proxyの振り分けを設定した方がいいかもしれません。 我々も最終的にはVueについてはDockerを使用せずにローカルサーバを使用することもできるように変更を加えています。
冒頭でも触れましたが、現在ではNuxt.jsやNext.jsなどWebサーバ機能を内包したメジャーなフレームワークも多く存在するためそういった手段を取った方がシンプルな構成にはなるかと思います。 しかし、実際に運用しているプロダクトでは必ずしもそういったフレームワークへの乗り換えが簡単に行えるとは限らず、悩んでいる方も多いのではないかと感じています。
この記事がそういった方に少しでも参考になれば幸いです。
ハコベルでは一緒に働くエンジニアを募集中です!
興味ある方はぜひこちらからご応募ください!
物流業界のDXを加速させる!ハコベル事業を牽引するテックリード候補を募集! | ラクスル株式会社
ラクスルのアドベントカレンダー全編はこちらから
Calendar for RAKSUL Advent Calendar 2021 | Advent Calendar 2021 - Qiita