はじめに
こんにちは、ハコベル事業本部 ソリューションスクラムチームの池松です。RAKSUL Advent Calendar 2021 13日目の記事になります。
まだ入社4ヶ月目ですがこういった記事をかかせていただき感謝。
本日は、直近で実施したDatadogを活用したシステムのパフォーマンス改善に関するお話をしたいと思います。
背景
ソリューションスクラムチームで開発するハコベルコネクトは、物流における配車業務のデジタル化により、業務自動化・情報一元化を行い、顧客の業務コスト削減を図るサービスです。
ありがたいことに、認知度ランキングでも一位を獲得させていただいており、導入社数も順調に増えてきています。
また、運送業界では12月はクリスマスやお正月などイベントが集中しており、1年で最も忙しい時期で、ハコベルコネクトへのアクセスもが多いときで通常の2〜3倍になることがあります。
こうしたユーザ数の増加や繁忙期の影響で、これまで違和感なく利用できていた機能も徐々にパフォーマンスが悪くなり、UXを著しく下げてしまう問題がありました。
そこでソリューションスクラムチームでは、ハイピークを迎える前にパフォーマンス改善を行うべく、既存の処理のパフォーマンス劣化を引き起こす原因の特定から行うことにしました。
ただ、原因の特定といっても、アクセスが集中するタイミングなどでたまたま重くなるパターンなどもあり、単一のアクセスログなどから調査・改善を進めても、全体への効果としてはイマイチなことが想像されたため、今回はDatadogを活用しました。
初めて利用しましたが想像以上に便利で、もはやDatadogなしでは生きられないぐらいになったので、今回はその機能や使い方について紹介させていただければと思います。
要約
- Datadog APMでは、エンドポイント単位/クエリ単位のパフォーマンス監視が可能
- それぞれの監視において、合計消費時間の上位から調査・改善していくことで、効率的なパフォーマンス改善が可能
- 様々な統計情報がわかりやすく可視化されており、パフォーマンスの劣化を引き起こす原因を素早く特定できる
- エンドポイント単位の監視においては、各リクエストの処理内容・処理時間が可視化されていて、支配的な処理を容易に確認可能
- クエリ単位の監視では、各クエリがどのエンドポイントから実行されたものかという確認も可能
- Datadog LogsやMonitorなど他の機能とも連携ができ、運用コストの削減にも効果的
Datadogとは
SaaS向けのデータ分析プラットフォームで、詳細については公式サイトをご確認いただければと思いますが、今回のパフォーマンス改善という目的では、以下のような機能を提供してくれます。
- ログ集約・検索
- すべてのサービス、アプリケーション、プラットフォームからログを自動収集
- ログ、メトリクス、リクエストトレース間をシームレスにナビゲート
- ログデータを可視化、アラート表示
- パフォーマンスの可視化
- 分散したシステム全体のリクエストをトレース
- エラー率やレイテンシーのパーセンタイル統計 (p95、p99 など) をグラフ化およびアラート
本記事の解説内容
実際に分析を行う前のインフラ設定やアプリケーション側の設定など、必要な作業はいくつかありますが、本記事ではあくまで導入したときの作業イメージや効果にフォーカスしてお伝えできればと思います
改善の流れ
Datadogの機能の一つであるDatadog APM (Application Performance Monitoring) では名前の通りアプリケーションのパフォーマンス監視を行えます。
Railsインスツルメンテーションを有効にした場合、リクエスト、データベース呼び出し、テンプレートのレンダリング、およびキャッシュの読み取り/書き込み/削除操作をトレースすることができます。
この状態で行える監視は主に2つあります。
1つは、エンドポイント単位のパフォーマンス監視、
もう1つは、クエリ単位のパフォーマンス監視です。
エンドポイント単位のパフォーマンス監視
こちらが画面の全体像です。
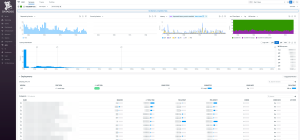
主要な可視化機能としては、以下になります。
- 時間帯毎のリクエスト数
- 時間帯毎のエラー数
- 時間帯毎のレイテンシ
- 時間帯毎の消費時間比率
- レイテンシの分布
- 指定期間内のエンドポイント別の統計情報
- リクエスト数
- 合計時間
- P50, P99
- エラー数・エラーレート
どれも有用な指標ですが、今回特に利用したのが指定期間内のエンドポイント別の統計情報です。
パフォーマンス改善は、やればやるほど効果はでるけど、基本的にはキリがなく、より少ない労力で高い効果を得られることが求められると思います。
そこで、エンドポイント単位でトータル時間の降順に並べ、上位に来るものの中でリクエスト回数が少ないものが、パフォーマンス改善すべき要素が多い可能性が高く、かつ効果が高いと判断して、それらを優先して見直すことにしました。
上記の指定期間内のエンドポイント別の統計情報から特定のエンドポイントを選択すると下記のようなエンドポイント別の統計情報ページに遷移します。
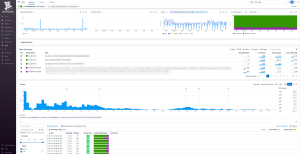
こちらでも時間帯ごとの各種指標やレイテンシ分布が見れ、かつ、以下のような情報も確認できます。
- エンドポイント内の各種処理ごとの実行時間と処理全体における割合
- DB/Webなどでの絞り込みも可能
- 対象のエンドポイントの各リクエストの発生時間帯とそれらのレスポンスタイム等
- レスポンスタイム順でソートすることができ、最も時間のかかったリクエストも確認可能
上記からエンドポイント全体で時間のかかった処理を統計的に判断できるとともに、局所的に重くなっているリクエストの詳細を確認することなどもできます。
更にリクエストを一つ選択すると、下記のようなリクエスト単位で視覚的にどの処理にどれくらいかかったかわかるような画面が表示されます。
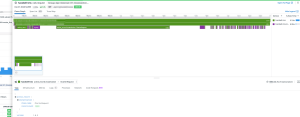
実際みてみるとあるモデルのActiveRecordのインスタンス生成で44%ほど使っていることがわかります。
(モザイクしているので見にくいですがなんとインスタンス数まで表示されます)
例えばこのパターンだと不要なインスタンス生成を行っていないかといった調査につなげることが可能です。
クエリ単位でのパフォーマンス監視
これだけでも十分なのですが、またクエリの観点から改善対象を調査することができます。
こちらがその画面の全体像です。
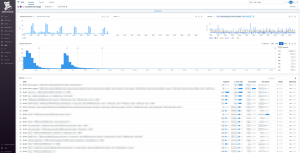
基本的にはエンドポイント単位でのパフォーマンス監視と同様ですが、クエリ単位での統計情報がこちらには表示されます。
こちらも同様にTOTAL TIMEで降順にならべて、上位の中でリクエスト数が少ないものに注目して調査を行いました。
実際に見てみると、対象のクエリがパルス的に発生していることがわかり、

また下記のようにこのクエリがどのエンドポイントからどれくらい呼ばれているか確認できる機能があるのですが、ある特定のエンドポイントからだけ発生するクエリだということがわかります。
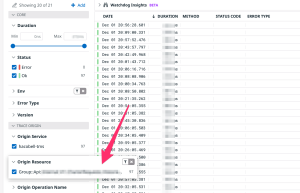
結果として、このクエリ自体重かったので別途処理の改善は行うとともに、別サーバから定期的にAPIが叩れていることが判明し、それらの連携方法を改善することでパフォーマンスの向上につなげることができました。
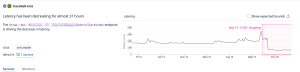
余談ですが、パフォーマンス改善が行われるとDatadogからお祝いしてもらえたりします。
(watchdogという機能があります)
その他Datadogの活用
今回はAPMに関する説明をメインでしましたが、Datadogには他にもLogsやMonitorなど様々な機能が提供されています。
軽くだけ紹介させていただくと、Datadog Logsはログの集約・検索を行うもので、ログのパース設定などを適切に行うことで検索したいログへのアクセスと統計情報の表示を簡単にできるようにしてくれるものです。
なんとこのLogsとAPMは相互連携可能で、先程のAPMのリクエスト詳細画面からLogsのリンクをたどることで、具体的にどんなリクエストパラメータが付与されていたかなどの確認ができるようになっています。逆にLogsからAPM側にたどることもできるので問い合わせ対応などをより効率的に行うことができます。
Datadog Monitorは、事前に設定したルールに基づき、その条件を満たした場合にアラートを出すことができる機能です。アラートはslack通知することも可能です。例えばですが、私達は5分おきに全エンドポイントに対して特定の秒数を超えるリクエストが発生した場合にアラートを出し、slack通知を送るようにすることでパフォーマンスの劣化を検知できるようにしています。
今後導入を検討している機能としてはDatadog Databasesがあり、こちらはDBと直接agentをつなげることで、クエリの実行計画なども収集することができるものになります。
ほんとDatadogすごいです...
ありがとう...Datadog...
また機会があればこのあたりも紹介させていただければと思います。
おわりに
ハコベルチームでは一緒に働くメンバーを募集しています!
興味ある方はぜひこちらからご応募ください!