
この記事は ノバセル Advent Calendar の 11 日目の記事です。
ノバセル テクノロジー開発部の吉田と申します。
今回の記事では、直近発表された論文を通じて生成 AI の将来像について考察していきたいと思います。
はじめに
生成 AI が普及し、総務省の調べによれば日本では個人の約 10%、企業の約 50%が日常的に生成 AI に触れているそうです。

現在、生成 AI のユースケースは増加し続けており、その拡大は今後ますます進んでいくと考えられます。
さらに、大規模言語モデル(LLM)が本来有する検索や要約といったプロセス自動化能力を基盤に、
タスクを包括的に完結させる「LLM ベースのエージェント」という概念が発展しつつあります。
この進化により、多種多様な情報を処理し、不確実性の高いタスクを遂行する能力が向上しており、特定の場面では人間以上に適した結果が得られる可能性が示唆されています。
そこで、生成 AI の裏側にあるアルゴリズムを理解することで、AI エージェントをより深く理解するためのヒントが得られると考え、
以下で関連する基礎研究を概観していきます。
参考論文 1: ReAct: Synergizing Reasoning and Acting in Language Models
論文リンク: ReAct: Synergizing Reasoning and Acting in Language Models
この論文は、「推論(Reasoning)」と「行動(Acting)」をシームレスに組み合わせることで、相乗的な改善をもたらすアルゴリズムを提案したものです。
日常生活において、人は「朝の出勤時にその日の段取りを考え、その結果を踏まえつつ行動し、さらに行動の結果を見て段取りを更新する」といった、思考と行動を反復しながら進めています。
どちらか一方に偏らず、両者を繰り返し組み合わせることで、より良い成果を得られることは日常的な経験からもうかがえるでしょう。
本論文では、これまで「推論のみ」や「行動のみ」に頼っていた脆弱なアルゴリズムに対して、
Reasoning と Acting を組み合わせた「ReAct モデル」を提案しています。これは、誤った情報を学習しやすい従来手法に比べ、
より頑健な出力が可能になることを示しています。
例を見てみましょう。
Acting のみ、Reasoning のみ(Chain-of-Thought: CoT)、そして ReAct を比較するために、FEVER というベンチマークを使用します。
FEVER は、質問に対し、対応する Wikipedia の記事があるかどうかで「支持する」「支持しない」「情報が無い」の 3 つに分類するタスクです。



最終的な答えはどの手法も正解にたどり着いていますが、ReAct は「Thought(思考)」「Action(行動)」「Observation(観察)」がバランスよく組み合わさり、人間が結論に至る過程を模したような動きをしています。
言語空間に対して、行動と思考を適切に組み合わせることで、より頑健な結論を導けることが直観的に理解できるでしょう。
参考論文 2: Reflexion: Language Agents with Verbal Reinforcement Learning
論文リンク: Reflexion: Language Agents with Verbal Reinforcement Learning
次に紹介するのは、ReAct に「Reflexion(内省)」という概念を付け加えた研究です。
これは、過去の失敗を反省材料として今後の行動改善に活かす仕組みを導入しています。具体的には、以下のような失敗パターンを考慮します。
1. 繰り返し行動の検出
同じ行動が何度も繰り返され、無益な観察しか得られない場合、
それを「非効率的な行動」としてフラグする。
例:エージェントが「引き出しを開ける」行動を3回繰り返してもアイテムが見つからない場合、
別の探索を検討する。
2. 行動の無効性
特定のアクションが無効である場合、それを記録し、将来の試行では回避する。
3. 探索の不十分性
環境内で特定のオブジェクトや情報が見つからない場合、
探索が十分でなかったと判断し、次回の試行では探索範囲を拡大する。
下図は Reflexion アルゴリズムのイメージです。
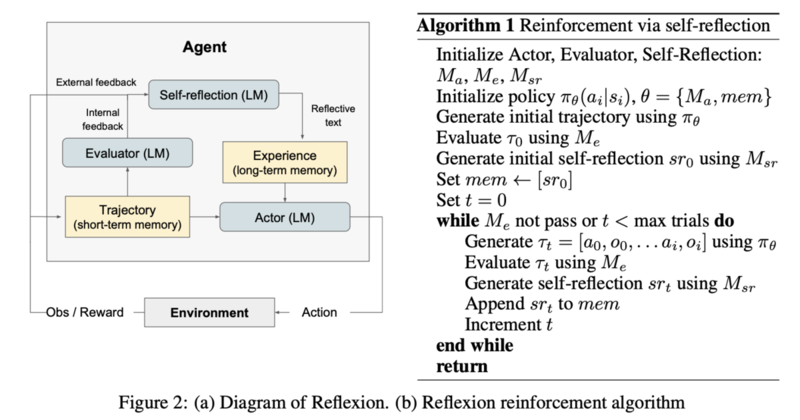
Reflexion では内部で反省プロセスを持ち、負の報酬条件を定義することで、
同じ行動を繰り返しても改善しない場合には別の行動へと誘導します。
これにより、ReAct が抱えていた「失敗結果を次に活かせない」という問題を克服し、
より高度な学習プロセスを実現しています。
AI エージェントへ
「こうしたアルゴリズムを知ることで何が得られるのか?」と思うかもしれませんが、
Reflection を活用した AI エージェントの例は既に登場しており、
アルゴリズムを理解することで、
・どの程度のタスクが実行可能なのか
・学習期間や学習内容の反映にはどれくらい時間がかかるのか
といったエージェントの特性を理解する上で有用な知見が得られます。
また、広告代理店業務のように必ずしもクライアント情報が完備されていない状況下で役立つアイデアとして、
不確実な情報下で情報量を増やす対話シミュレーションモデル
の提案もなされています。これは、不確実性を減らすために、エントロピー計算を用いて対話シミュレーションを行い、
どのような対話が不確実性低減に有効かを探索するアイデアです。
さいごに
LLM の基礎研究を知ることで、今後必要とされる AI(LLM)エージェントへの理解や開発へのきっかけが得られます。
今回ご紹介した研究はその一部に過ぎず、この領域は急速に発展しています。
先行研究から学び、多くの知見を取り入れることで、有益な AI エージェントをクライアント様と共創していきたいと考えています。