こんにちは、ラクスルの印刷事業でエンジニアをしている西元、木下です。
普段は印刷事業のプロダクト開発に携わっていますが、9月に開催された Hackweek では日常業務とは異なるデータ分析に焦点を当てたテーマに挑戦しました。
今年の Hackweek のテーマは "Co-pilot for Industries" です。
私たちは、ラクスルが持つ膨大なデータを活用し、ユーザーのビジネス(産業)を深く理解した上で、次の一手を提案するレコメンド機能 「ススメル」 プロダクトの開発に挑みました。
プロジェクト「ススメル」とは?
「ススメル」という名前には、3つの意味が込められています。
- 最適な商品を「薦める」 (Recommend)
- 注文プロセスを「進める」 (Process)
- 現状のその先へ「進め!」 (Go beyond)
ラクスルは印刷、ノベルティ、アパレルなど、さまざまな商品を取り扱っています。
商品の種類が多く、ユーザーが能動的に探し出さないと欲しい商品に出会えないという課題がありました。
そこで、「あなたの産業なら、今はこれが必要ではありませんか?」と先回りして提案する、Co-pilot(副操縦士)のような存在があると便利なのではないかと考えました。
産業を軸にしたレコメンド
通常のレコメンドでは、user_id × item_id の行列を組み、user_id をユーザー軸として行列分解することが多いかと思います。しかし、BtoB であるラクスルの場合、1人のユーザーの行動履歴が少ないケースや同じ企業の複数名がローテーションで購入する場合も多々あり、user_id だと十分に傾向を取れない可能性がありました。
そのため、今回は user_id の代わりに industry_id をユーザー軸として扱い、「産業」ごとにモデルを学習させるアプローチを採用しました。
アーキテクチャと技術選定
Hackweekの1週間という限られた期間で、実データを用いたレコメンド機能を作るため、以下の構成を採用しました。
- データウェアハウス: BigQuery
- 機械学習: BigQuery ML (Matrix Factorization)
- API: Cloud Functions
レコメンドの実装方式については、以下のような選択肢を比較検討しました。
マネージドサービスを使う案
- AWS
- Amazon Personalize
汎用的なレコメンド機能をフルマネージドで提供するサービスです。ただし BigQuery とのデータ連携基盤を別途用意する必要があります。 - Amazon SageMaker
独自モデルの構築や自律的な改善が可能で柔軟性は高い一方、インフラ構築や運用コストが大きく、Hackweek 期間での活用は難しいと判断しました。
- Amazon Personalize
- Google Cloud
- Vertex AI
高いカスタマイズ性と拡張性があり、BigQuery や Gemini とも連携しやすいプラットフォームです。ただし今回のスコープでは、ここまでの柔軟性は必須ではありませんでした。 - BigQuery ML
今回採用した方式です。SQL だけで学習から推論まで完結でき、Cloud Functions と組み合わせてシンプルな構成で API 化できます。
- Vertex AI
- AWS
自前実装を行う案(Python / OSS ライブラリ)
- Surprise / LightFM / Implicit / TensorFlow Recommenders など
協調フィルタリングやハイブリッドレコメンドを柔軟に組み立てられますが、学習・推論用のサーバーやスケジューラなどの基盤を別途構築する必要があります。
- Surprise / LightFM / Implicit / TensorFlow Recommenders など
最終的には、次の理由から BigQuery ML を選択しました。
- BigQuery 上の実データに直接アクセスして学習・推論できるため、データ連携の実装コストを抑えられること
- 普段レコメンドに携わらないメンバーがHackweek の期間内で、モデルの試行錯誤から API 化まで一気通貫で行えること
- 追加のインフラ構築をほとんど必要とせず、小さく始めて後から拡張しやすいこと
行列分解モデル
まずは伝統的な手法の一つである行列分解モデルを採用することにしました。 今回の取り組みで効果が確認できれば更なるモデルの改善を継続的に行えるため、最初に動作するものを作ろうという考えで選択しました。
行列分解モデルは、ユーザー数とアイテム数の行列で表せる傾向を、「ユーザー数 × ハイパーパラメータ k」のユーザー行列、「ハイパーパラメータ k × アイテム数」のアイテム行列の内積で近似する手法です。
ハイパーパラメータ k は BigQuery MLでは NUM_FACTORS であり、結果を見ながらこの値もチューニングしていきました。
行列分解を用いたレコメンド手法には、明示的フィードバックを扱うものと暗黙的フィードバックを扱うものがあります。
明示的なフィードバックに基づく方法は、ユーザーの商品に対する評価など明示的に得られた評価を使う方法です。一方、暗黙的なフィードバックに基づく方法では、ユーザーの行動ログなど直接的ではない情報を使う方法です。
今回利用したのはユーザーの購入履歴や行動履歴であるため、初めは暗黙的フィードバックが適しているのではと考えていました。しかし、モデルのチューニングをしていく中でテール商品がレコメンドのランキング上位にくるといった、ユーザーの傾向と一致しない結果が得られたため、最終的には明示的なフィードバックに基づく行列分解モデルの結果を採用しました。
BigQuery MLでの行列分解モデル
実際に試したクエリを一部抜粋したのが下記です。
購入履歴や行動履歴をインプットとして、産業 × 商品 の組み合わせでモデルを作成しています。
ラクスルではよく購入・閲覧される商品とそうではない商品の差がとても大きいため、評価値(rating)を標準化してモデルを作成しました。
CREATE OR REPLACE MODEL `model` OPTIONS ( MODEL_TYPE = 'matrix_factorization', -- 行列分解モデルを採用 FEEDBACK_TYPE = 'explicit', -- 明示的 USER_COL = 'industry_id', -- ユーザー軸として利用する列(ここでは産業 ID) ITEM_COL = 'category_name', DATA_SPLIT_METHOD = 'AUTO_SPLIT', NUM_FACTORS = 10 -- ハイパーパラメータのため検証してチューニング ) AS SELECT -- ユーザーの産業 × 商品で購入履歴や行動履歴を集計し、重みづけをする industry_id, category_name, 1 AS rating -- 実際には評価値の標準化を行った FROM (省略)
このモデルを使って作成したレコメンドリストは実際の購入履歴や行動履歴の集計と見比べ、どのパラメータが適しているかを評価し、チューニングしていきました。
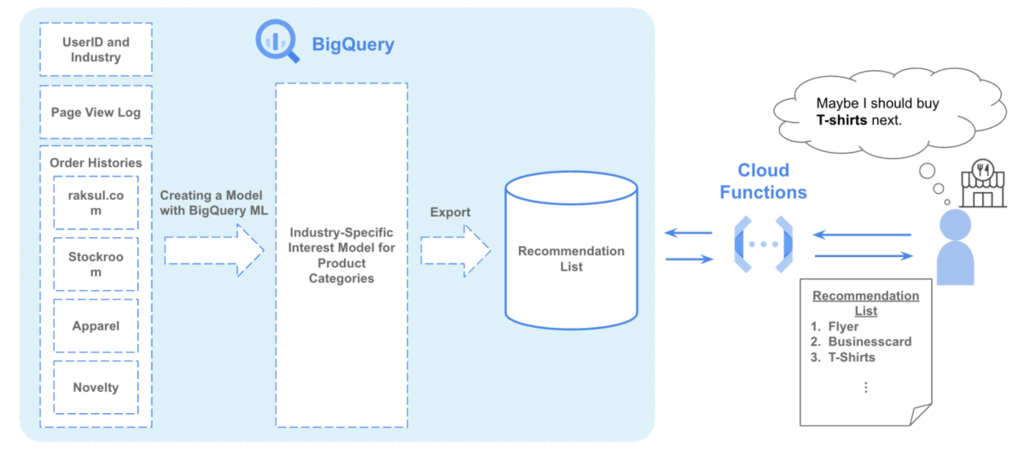
処理フロー
将来的には各ECでレコメンド欄を表示する活用を考えているため、産業に対するレコメンドリストをAPIで取得できるようにしました。 完成した処理フローは下記のとおりです。
- BigQuery 上に購買情報や行動履歴を収集し、クレンジング
- BigQuery ML に情報を渡し、産業 ID ごとに学習させモデル作成
- 産業 ID ごとのレコメンドリストを生成
- 産業 ID のリクエストをもとにCloud Functions経由でレコメンドリストを返却
成果物
こちらが成果物のデモになります。
産業を選択すると、その産業に対する商品をランキング表示でレコメンドします。 文字のみだと味気なかったため、産業と商品を組み合わせた画像をVertex AIで生成してサムネイル画像としています。
まとめ
今回作成したレコメンドリストでは産業ごとにレコメンドのランキングが変動し、完璧ではありませんが上位は経験値とも一致している結果を得られました。 実際作業できたのは3日ほどでしたが、データの抽出からモデル作成まで BigQuery 内で完結したため、インフラ構築の手間を大幅に削減でき、実際にレコメンドを表示する部分まで作成できました。
Hackweek では普段の業務のナレッジを活用しつつ、普段とは違う視点で自社のサービスを考える良い経験となりました。