こんにちは!ラクスル事業本部でサーバーサイドエンジニアをしている久冨(@tomi_t0mmy)です。
今年もRubyKaigiがやってきますね!あの熱気をまた感じられるのかと思うととてもワクワクします。
私は昨年、新卒1年目でRubyKaigiに初参加しました。
初心者にも温かく接してくださるRubyistの皆さんのおかげでとても楽しい3日間だったのですが、昨年の私の感想としては……
「楽しいけど、セッションの内容は全然理解できない(泣)」
でした。
セッションの内容を理解できなくても楽しめたけど、理解できたらもっと楽しいはず……!!!
ということで、今年は昨年よりも予習の量を増やし、かつ分野を絞ることで1つでも「理解できた!」と思えるセッションの数を増やすことを目指すことにしました。この記事では、RubyKaigi初心者の私が予習した内容をアウトプットしていこうと思います。このブログがどこかのRubyistの助けになれば幸いです!
今回私が勉強したのはパーサー関連です。 Rubyは自由自在に書けるという強みがあり、その特性を活かしたTRICKというコンテストもあります。昨年のRubyKaigiでもキーノートでTRICKについて説明されていましたが、こんなにも変幻自在なコードを書けちゃうのは面白いですよね!
こんなコードを実行している裏側はどうなっているのか?と興味が湧いたので、今回はRubyのインタプリタ、その中でもコードの意味を解析するパーサー周りについて勉強してみることにしました。
パーサーとは
Rubyのパーサーに興味があるとはいえ、私はインタプリタの仕組みなどをちゃんと勉強したことがなかったので、一般的なインタプリタ・パーサーの仕組みの勉強から始めました。
インタプリタの構成
一般的にインタプリタの処理は以下のようなフローで行われます。
- 字句解析
- 構文解析
- 中間コード生成
- 最適化
- 機械語生成
それぞれのフローについて役割、実行の主体、アウトプットをまとめました。
| フロー名 | 役割 | 実行の主体 | アウトプット |
|---|---|---|---|
| 字句解析 | ソースコードを意味のある最小単位(トークン)に分解する | 字句解析器(lexer) | トークン列 |
| 構文解析 | トークン列から言語の文法に従って意味のある構造(構文木)を作成する | 構文解析器(パーサー) | 抽象構文木(AST) |
| 中間コード生成 | ASTから中間表現に変換する | コードジェネレーター | 中間表現(IR) |
| 最適化 | 中間表現を効率的な形に変換する | オプティマイザー | 最適化された中間表現 |
| 機械語生成 | 中間表現を実行可能な機械語に変換する | コードジェネレーター | 機械語コード |
今回はこの中でも構文解析とパーサーの生成について掘り下げていきます。
言語の文法の定義方法
構文解析では、字句解析によって生成したトークン列と文法から意味のある構造(抽象構文木)を作成します。そのためには言語の文法を定義する方法が必要です。
文法を定義するための記法として代表的なものがバッカス・ナウア記法(BNF)です。BNFでは以下のように文法を定義します。
<数字> ::= 0|1|2|3|4|5|6|7|8|9 <英字> ::= a|b|c|d|e|f|g|h|i|j|k|l|m|n|o|p|q|r|s|t|u|v|w|x|y|z <名前> ::= <英字>|<名前><英字>|<名前><数字>
上記は以下を意味しています。
- <数字>は0~9のいずれか
- <英字>はa~zのいずれか
- <名前>は <英字>、<名前><英字>、<名前><数字> のいずれか( <名前><英字> は <名前> の後ろに <英字> をつけたものを表す)
この場合における0~9やa~zはこの文法規則においてこれ以上置き換えることができません。このような記号を終端記号と呼びます。終端記号以外の記号は非終端記号と呼びます。この例では <英字>や<名前>といったものが非終端記号です。
このように決まった記法で定義された文法をもとにしてパーサーが作成されます。実際には、バッカス・ナウア記法を拡張した拡張バッカス・ナウア記法が多く用いられます。
抽象構文木
構文解析のアウトプットである抽象構文木(AST)は、文法構造をツリー構造で表したものです。試しにRubyを構文解析するためのライブラリであるRipperを使って3 + 5 * 2 というプログラムの抽象構文木を出力してみましょう。
以下のコードを実行してみます。
require 'ripper' require 'pp' code = "3 + 5 * 2" ast = Ripper.sexp(code) pp ast
すると、以下のような出力が得られます。
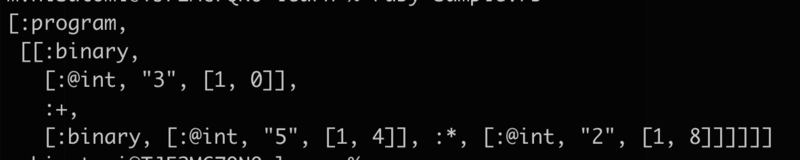
これはすなわち、以下のようなASTが得られたことになります。
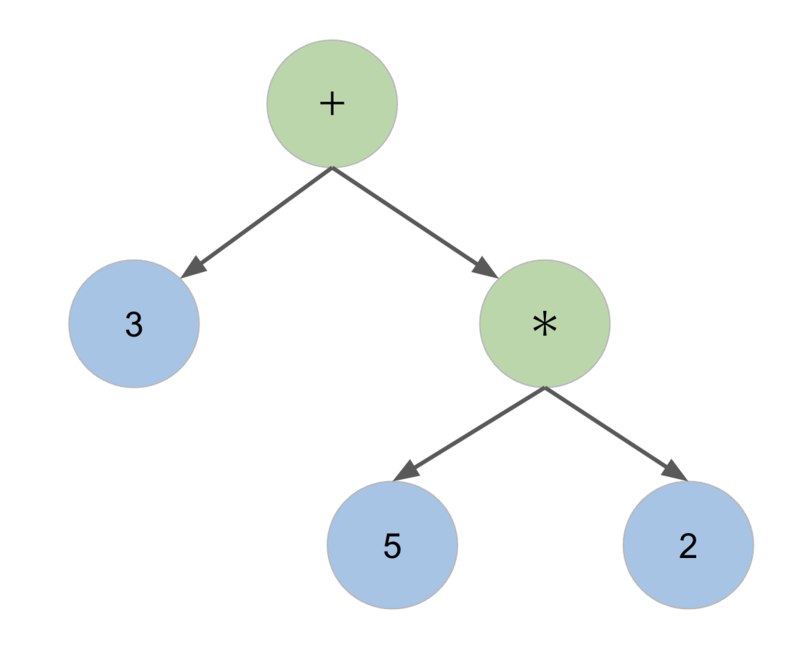
構文解析のアルゴリズム
構文解析では、字句解析で得られたトークンと文法の定義をもとに解析を進めていきます。その解析の際のアルゴリズムには大きくトップダウン型とボトムアップ型の2種類があります。
トップダウン型とは、プログラムを左から右に走査し、非終端記号を終端記号に置き換えていくアルゴリズムのことです。これだけだと分かりにくいかもしれないので、私の理解を図を用いてざっくりと説明しようと思います。
以下のような規則からなる文法があったとします。
S ::= aAd (1) A ::= b|c (2)
abdというプログラムが与えられたとき、トップダウン型では以下のように解析します。
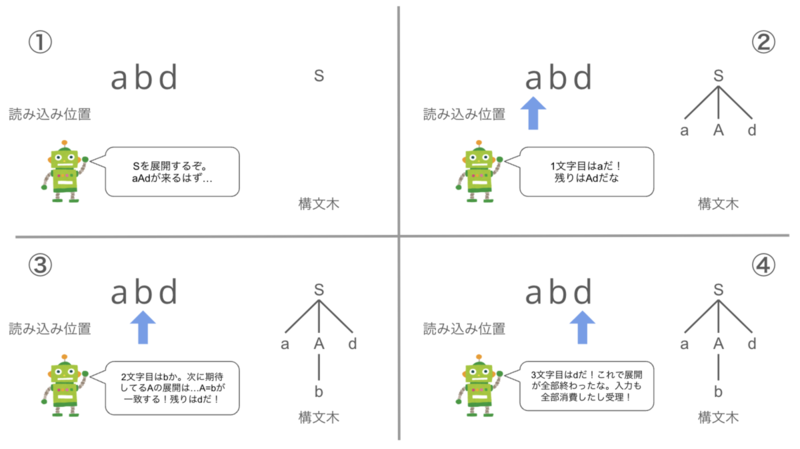
トップダウン型では読み込むものの形を仮定するため、文法に加える制限が大きく適用範囲は比較的狭くなります。また、文法の形がそのままパーサープログラムの形になるため、プログラムは比較的分かりやすいのが特徴です。
トップダウン型の例としてはLL法などが挙げられます。
一方、ボトムアップ型はプログラムを左から右に走査し、終端記号を非終端記号に置き換えていくアルゴリズムです。
また私なりの理解を図にしてみると、先ほどと同じ文法規則・プログラムが与えられたときボトムアップ型では以下のように解析します。
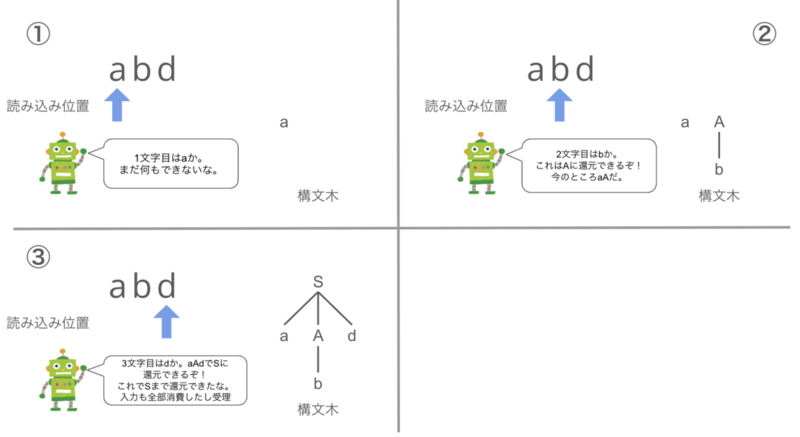
このように、ボトムアップ型では「確定したものが出てきたら順次置き換える」という戦略を取ります。
トップダウン型と比較して考えると、ボトムアップ型はその適用範囲の広さが特徴的です。またパーサープログラムの実装が分かりにくいものになることが多いことも特徴のひとつで、パーサージェネレーターを用いてプログラムを自動生成することが多いようです。
ボトムアップ型の例としてはLR法、SLR法、LALR法などが挙げられます。
パーサーの実装方法
パーサーの実装方法には人が手書きで書く方法とパーサージェネレーターを用いて自動生成する方法があります。
パーサージェネレーターとは、文法規則を記述したファイルをもとにパーサーのプログラムを自動生成するものです。代表的なものとしてYacc、Bisonなどがあります。
パーサージェネレーターを使うメリットとしては以下のようなものがあります。
- 複雑なパーサープログラムを効率的に開発できる
- 文法の定義とパーサープログラムの実装に乖離がなくなる
Rubyのパーサーの歴史
ここまでの内容を踏まえて、次はRubyのパーサーについて理解を深めていきます!
今年のセッションを聞くにあたって、Rubyのパーサーの歴史についてざっくりと理解しておくと良さそうだと思ったので時系列順でまとめてみました。
CRuby誕生
CRubyはまつもとゆきひろさんが作った最初のRuby実装です。当初はパーサージェネレーターとしてYaccを用いていたようです。このYaccの入力となる文法規則を記述したファイルがparse.yです。その後、YaccからBisonに移行されます。
この頃の実装ではパフォーマンスが重視されており、パーサーとランタイムが密結合していたようです。
Rubyツールの多様化とパーサーの移植性問題
その後、JRubyなどの実装やRipperなどのパーサーライブラリといった、CRubyのパーサーに依存する様々なツールが作られます。しかし、CRubyのパーサーがランタイムと密結合しているために、各ツールでCRubyと同じパーサーを再実装し、CRubyのアップデートに追従する必要があるという課題がありました。
Lrama誕生
Yuichiro Kanekoさんが新たなパーサージェネレーターであるLramaを作成し、CRubyに追加されます。LramaはBisonの置き換えを目指して再実装されたパーサージェネレーターです。
これまではCRubyはBisonに依存していましたが、Bisonの細かなバージョンでうまく動作しない、Bisonだと思い通りに拡張することができない、といった課題が発生していました。Lramaの追加により”脱Bison”が達成でき、上記のような課題の解消に貢献したということですね。
Lramaは現在も改善が続けられています。特に、上記で述べた移植性の問題の解消に向けてユニバーサルパーサー、すなわちRuby本体から独立して動くパーサーの実現に向けて作業が行われているようです。
Prism誕生
Lramaの導入と同時期に、エラー許容性のあるユニバーサルパーサーとしてPrismが実装され、Ruby3.3でdefault gemとして追加されました。Ruby3.4ではparse.yから生成されるパーサーに代わり、Prismがデフォルトのパーサーとして採用されたようです。
エラー許容性とは、パーサーの解析中に構文エラーが発生しても解析を継続できる能力のことです。SorbetやRuby LSPなどの登場により、エラー許容性の重要度が高まっています。
上記の取り組みとともに、Prismプロジェクトはユニバーサルパーサーの実現にも注力しました。Rubyエコシステムの様々なパーサーメンテナーと緊密に連携し、ユニバーサルパーサーとしての要件を整理していったようです。現在では様々なプロジェクトがPrismを使用しています。
Prismは手書きで実装されたパーサーなので、パーサージェネレーターであるLramaとは対照的ですね。
今年気になるセッション
最後に、今年のRubyKaigiで個人的に気になるセッションを紹介していこうと思います!せっかく勉強したのでパーサー関連のセッションに重点的に参加したいです。
Make Parsers Compatible Using Automata Learning
Ruby3.4からデフォルトになったPrismが、従来のパーサーであるparse.yと高い互換性を保っている方法について説明するセッションです。ここではオートマトン学習という手法に着目するようですね。このブログでは省略してしまったのですが、構文解析のアルゴリズムの裏側ではオートマトンを多用しているので、興味のある方は事前に調べておくとより理解が深まるかもしれません!
Ruby's Line Breaks
Rubyの”改行”の扱いに着目したセッション!これまたニッチな話題ですね。しかし、言われてみればいろんな意味を持ちうる改行がどのように処理されているのか気になります。 Lramaの作者であるYuichiro Kanekoさんの発表ということもあり、注目のセッションです!
Dissecting and Reconstructing Ruby Syntactic Structures
parse.yの文法規則の構造について深掘るセッションのようです。parse.yに記載されている文法規則は非常に複雑とのことなので、一体どのように読み解いていったのか、また読み解いた結果どのような示唆が得られたのか非常に気になります!
The Implementations of Advanced LR Parser Algorithm
Lramaのパーサーアルゴリズムの改善についてのセッションです。ボトムアップ型であるLALR法をさらに進化させたIRLR法というアルゴリズムについて、またLramaへの実装について説明してくださるようです。 ゴリゴリのアルゴリズムの話のようですね!LALR法だけでも予習していかねばと身が引き締まります…!
最後に
パーサー関連の話題は勉強すればするほど 沼 奥が深くて面白いですね!
最近のRubyにおいてはLramaとPrismという2つの大きなトレンドがあるようなので、両者の違いに着目しながら聞いてみたいです。
それでは、Rubyistの皆さんと松山でお会いできるのを楽しみにしています!
参考文献
Ruby: 2024年までのPrismパーサーの長い歴史を振り返る(翻訳)|TechRacho by BPS株式会社
Rubyパーサーを一新するprism(旧YARP)プロジェクトの全容と将来(翻訳)|TechRacho by BPS株式会社